So you still want to use Jira in your SAFe-going organization? Here’s another, an even simpler way to do it.

– Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius, and a lot of courage to move in the opposite direction
– E.F. Schumacher
Back in May 2018, I posted about the The simplest way to run SAFe with Jira. After that, I’ve at clients as well as in attending other Jira-spouting companies’ breakfast seminars run into more set-ups which attempt the same – some better, some worse, but definitely more complicated.
Now, I don’t here intend to go into the details of why you would want to run SAFe with Jira and the fundamental challenges which lie in that direction – these are quite thoroughly described in my previous post.
But alas, there is an even simpler way to run SAFe with Jira, which may be too obvious to notice at first.
Confusion in the plugin land
I’ve had the set-up described below in my mind for some time already, but it took something I read this very morning on the ALMWorks’ Structure for Cloud Google discussion group which got me sparked about returning to the topic.
This is what I saw:
[Structure’s] customers split into two camps to deal with the discrepancy of how Jira does things and how SAFe prescribes it.
- Some customers adapt the wording in their process to adapt to Jira’s […] They reason that a feature by any other name, is still a feature. […] They also work diligently to make sure everyone knows that instead of Epic -> Feature -> Story, their hierarchy is […].
- A more common case is to adapt Jira to [match SAFe’s terminology]. They will link their Epics to Features and have Features link to Stories. They will define a specific issue link that reflects this relationship and will not use Jira’s built-in Jira of Stories under Epics. For example, they will use an issue link called “Implements”, so in their hierarchy, an Epic is implemented by Features, and in turn Features in implemented by Stories.
Now, as you might have guessed, I don’t recommend either of these approaches. There are simpler set-ups.
Another Simplest Way – The SuperVanilla
This set-up – let’s call it “SuperVanilla” is so obvious that was bound to be overlooked. Let’s walk through how to set up in terms of issue types, workflows, boards and progress metrics.
The set-up is such that for each SAFe portfolio, you can create a separate project using the steps below. However, do first consider whether you really have many separate portfolios as defined in SAFe – in all but the very largest of companies, you really don’t.
I also don’t suggest that you’d take this model as the prescription you follow until the end of time. What I definitely am saying is that only start complicating things when you are really, persistently, in pain without doing so.
Also, if you have teams which prefer their own way of keeping track of their Sprint level work, I would not impose Jira on them. What matters is keeping the Features’ progress up to date.
Furthermore, since in this set-up everything is in the same Jira project, if you want to restrict the visibility of certain issues, you can apply issue-level security. But I would not suggest going that way either.
OK, let’s get started!
Issue types
SAFe has a three-level hierarchy of Epics, Features and Stories. Never mind here the special terms they’ve cooked up for “Epics that can be completed by a single program / a single value stream”.
Jira, too, has a three-level hierachy – at least sort of – Epics, Stories and Sub-tasks.
If we forget about the problems that come from having a fixed-level requirements taxonomy with named levels – most practitioner audiences I’ve spoken to do so as well – we get SAFe’s levels by simply removing the extra issue types and renaming the rest.
The end result should look like this:
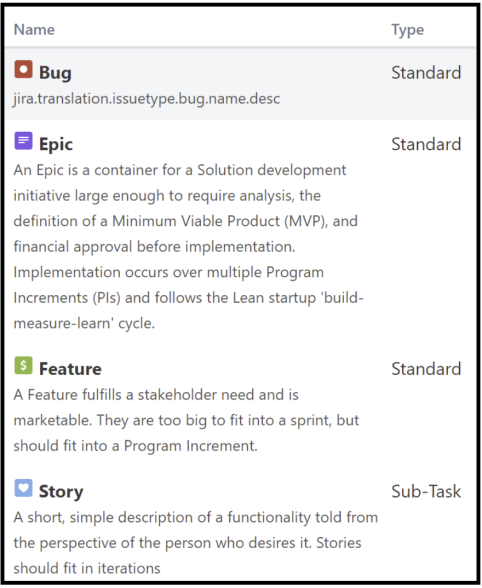
I usually recommend to keep Bug as a separate issue type.
Workflows
Then, let’s look at the workflow configurations. Here, I’ve gone with the simplest solution that could possibly work – the same workflow for all issue types:
FUNNEL for ‘everything that comes up’, BACKLOG for things which are understood well-enough so that we can work on them, and an ANALYSIS stage to separate those.
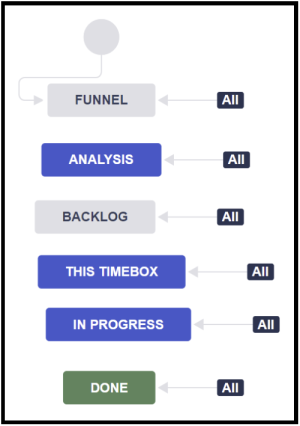
Program Increments (PI) are modeled using the states THIS TIMEBOX and IN PROGRESS. Those Features which are in a PI which yet have no stories ongoing are in the THIS TIMEBOX stage, while those which have work ongoing are in the IN PROGRESS stage.
Another thing to consider – which I have not added here for the sake of simplicity – is that you will want to have a REJECTED stage to keep FUNNEL clean and to a manageable size.
Boards
The simplest solution is of course to use a single Jira Kanban board. Don’t use a Scrum board – Jira’s sprint functionality is very much glued-on-afterwards and thus rather convoluted. Definitely, it will not make things simpler.
And furthermore, with set-up there is no need to use Jira’s sprint functionality it at all.
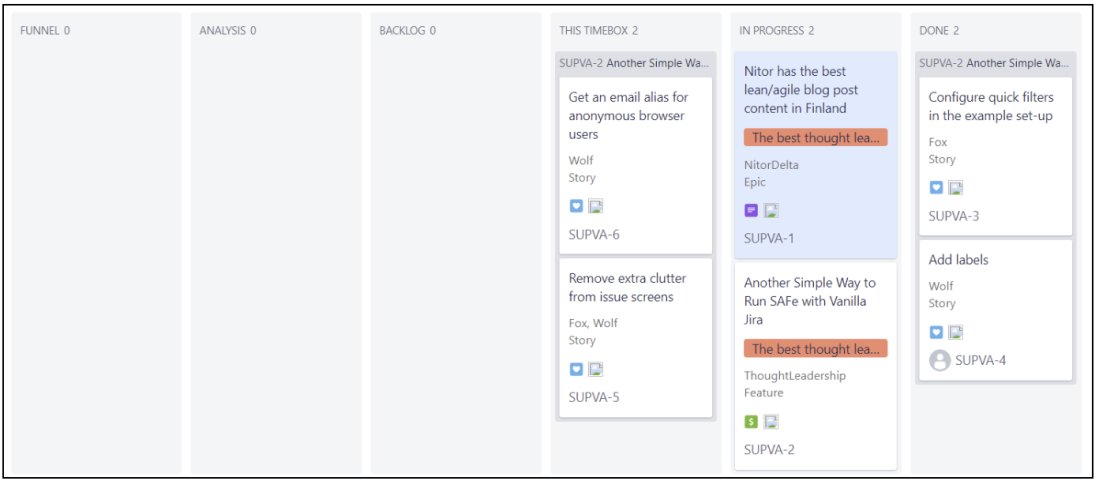
The first step there is to set up columns that match the workflow. The result will look like this:
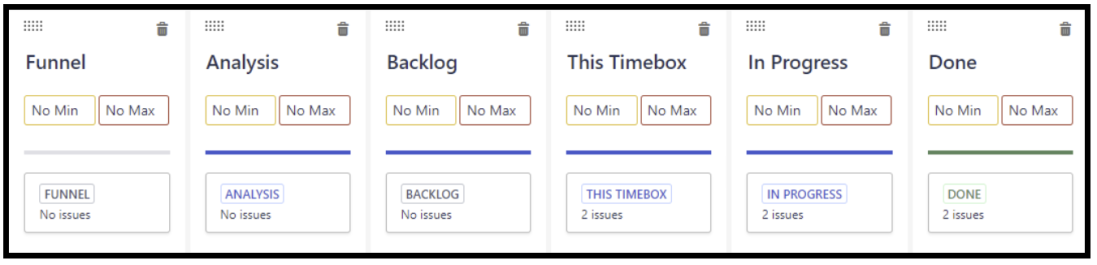
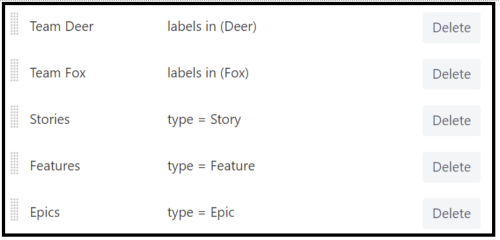
The general filter simply looks up all the issues in the project. On top of that, we create three quick filters to discern between Epics, Features, Stories and Bugs. Here are the filters for the three first mentioned, doing the Bug filter is left as an exercise for the reader:
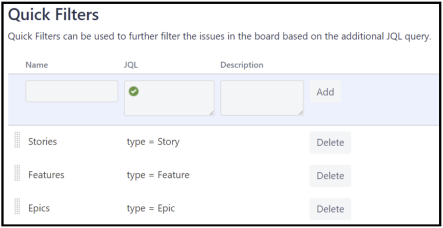
Teams and trains
In addition, since all the teams’ work is in a single project, we need some way to discern and possibly also filter what issues – if any, belong to which team and train.
I discourage using components to denote teams or trains – those are best used to model – surprise – components.
Also, using a single login to denote an entire team like I suggested in my previous post is both forbidden as well as a tad too radical for most organizations.
While we could configure groups to denote different teams, using labels is the simplest route to take. They can easily be seen on virtually any Jira screen and are quite easy to use.
In the case when there are several teams (or trains) who need to collaborate on a story, applying several labels is easy, and using labels can also be applied when there are multiple trains who work on the same solution. So, now we have the following quick filters:
And the board itself looks like this; just use different filters to look up only those items you are interested in.
Progress metrics
The most obvious metric you might want to have is to follow an Epic’s progress over time. To make that possible, create another quick filter which looks up the Epic’s Features using the following JQL
“Epic Link” = [issue key of the Epic] AND type = Feature
Note, that without the type limitation, the query will also bring up also the Stories under the Feature – which we do not want.
Then, look up the cumulative flow diagram, and apply the quick filter. Since Jira’s cumulative flow diagram counts the issues and does not weigh them with e.g. story points, it’s best to strive for Features of a uniform size. But then again, that’s what you should pursue anyhow.
While you have to a quick filter for each individual Epic whose progress you wish to monitor, the configuration is not a huge effort. You probably don’t have that many Epics simultaneously launching – or if you do, looking up a particular Epic’s progress is not your most pressing problem.
Anyhow, once you’ve created the first one, it’s a simple copy-paste operation in the quick filters where you simply replace the key of the Epic.
Looking up a Feature’s progress is also fairly straightforward – look up the related stories directly from the Feature itself, and discuss with the team(s) involved. Since Features should not span that long, there is probably not a need for explicit progress tracking as a function of time.
But, if you want to, the steps to create a progress metric for Features are exactly the same as for Epics.
As for Sprint burn-ups, pick your team, filter based on label, look up the cumulative flow diagram and there you have it.
Anything else?
So there you have it – possibly the simplest possible way to run SAFe with Plain Vanilla Jira. If you think I have overlooked something important, feel free to drop me a note and I’ll try to accommodate it.

I have enjoyed both of your approaches to using JIRA outright to implement SAFe. A vanilla approach to a SAFe implementation using more of the products from Atlassian’s suite (Confluence + JIRA + Portfolio) would be great.
LikeLike
Is there a trick to using Jira’s WIP limit on these kinds of board which many teams use? For instance in SAFe Program Management might have a WIP limit on features and the teams have different WIP limits on stories. Is there a way to visualize that in your approach?
I feel that one of the biggest problems is that we (as humans) tend to skip the WIP limit, at least in the beginning.
LikeLike
I believe using Jira’s WiP limits is something this kind of setup has to live without
LikeLike