Your favourite backlog management tool is back. Free forever, more powerful, and with a vengeance.Sign up here!
Background color of the logo is homage to my current employer, DNA, whose push towards being a frontrunner in its industry on AI lighted the spark needed to resurrect Agilefant
“Projects, organizations, shareholders, government loans, convertible bonds, colleagues, co-founders, stock options, codebases – they come and go. Agilefant is a lifestyle.” – Dr. Agilefant
On the 3rd of April 2026 I decided to try my hand at rebuilding Agilefant with AI-powered tools. Two weeks later I had a more powerful version of what we had before. I used Lovable, Supabase, Github Copilot, Cloudflare and screenshots and questions to Gemini when I ran into trouble.
Why? Because as doing keeps getting faster and faster with modern tech, skillful thinking and deciding on what to actually do becomes increasingly important.
Agilefant’s mission statement goes as follows:
For free, support skillful thinking to unlock new levels of value production for people, organizations and society
I have some war stories from the two weeks of putting this together, as well as a rich history of Agilefant’s origins – but I’ll share those later.
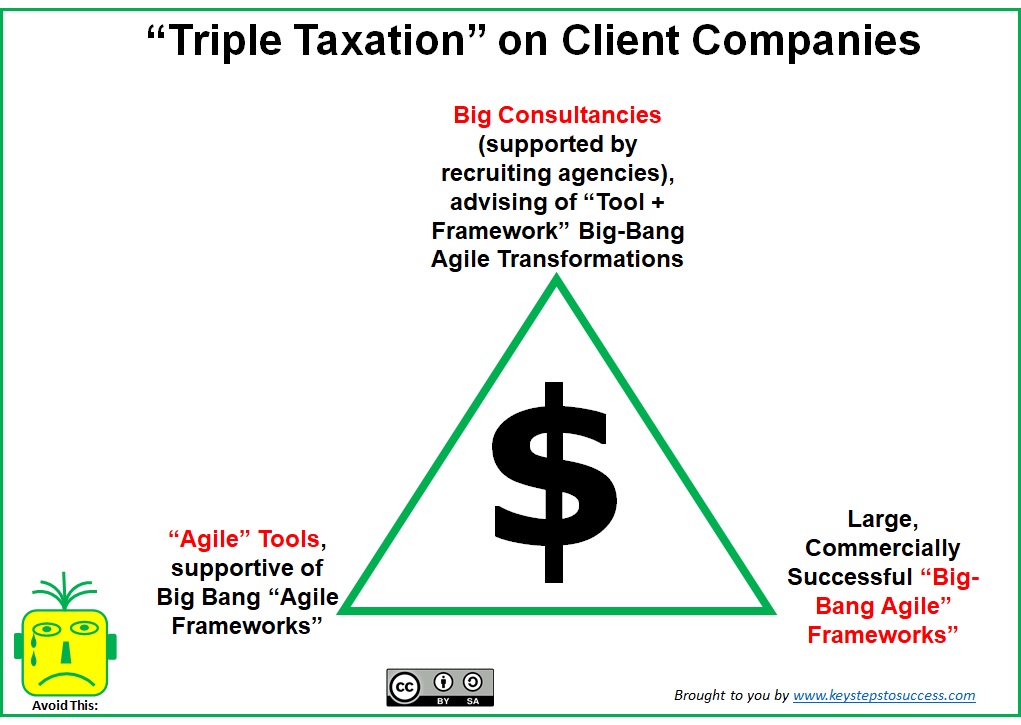
Suppose the company you work in has requested one of the big consultancies to roll out their favourite scaled agile framework to you with a big bang? It most often is a version of the so-called “Spotify model”. Here is a curated selection of background, readings and videos you want to be familiar with if you find yourself in such a situation.
A part of the so-called Spotify model from Kniberg and Ivarsson’s 2012 article
“I know what I wouldn’t have done, and that is outsourcing the problem to [a big consultancy]… and have them find a solution. The research results are clear. The solutions must come from within the organization.” – John Kotter
What is nowadays called the “Spotify model” is a snapshot of how Spotify in 2011 envisioned to work in the future. Its origins can be traced back to this 2012 article, written by Henrik Kniberg and the former engineering lead and agile coach from Spotify Anders Ivarsson.
Based on that article, and a great series of videos by Henrik Kniberg on the Spotify engineering culture (part 1 here, you can find the rest quite easily), people coined the presented way of organizing as the “Spotify Model”.
SAFe and “Spotify Model” contain a lot of the same genetic material. Squads are Teams, Tribes are Trains, Chapters are the line organization of the dual operating model proposed by Kotter and later on adopted by SAFe, and Guilds are communities of practice. The rest of the roles in the original 2012 article map quite directly to similar roles in SAFe.
There are videos out there which compare Spotify and SAFe, this one by Joakim Sunden, a former agile coach from Spotify and the person who coined the term Tribe. Furthermore in the “Spotify Model” teams are supposed to have an entrepreneurial attitude (similar to that of Marty Cagan’s empowered product teams) and figure out by themselves what to do. In SAFe, the teams are more akin to a delivery organization.
Comparing to LeSS, the key differences are that teams in the “Spotify model” have their own backlogs and there is a product owner per team. These are both something LeSS advises against. Further, emphasising team entrepreneurship doesn’t encourage the cross-functional learning which needed to constantly shift to work on the most important things.
Rather, it can limit teams to their own areas, hindering collaboration and overall product success. Also, the Team PO role hinders the teams to handle coordination by themselves at the developer level, which leads to increasing the wastes of delay, inventory (via intermediate artifacts such as requirement specs) and coordination bloat.
Why do big consultancies favor the “Spotify Model”?
In my opinion there are four main reasons, which work together:
The “Spotify model” is very similar to SAFe. With the difference that you don’t have to deal out part of the profits to Dean Leffingwell & the folks at Scaled Agile. As a consultancy, you can invent your own jargon and practices (which can most often be directly mapped to SAFe) to fill in the gaps of the “Spotify model” and get the client hooked on your version.
And just like with SAFe, these additional details provide the legacy organization a scaffolding with places to hide in, so you really don’t have to change all that much. Departments can call themselves tribes, component teams become squads, and system owners can remain system owners – you don’t even have to change the term. Finally, with the team product owners handling the brunt of coordination, the inefficiencies of “low-cost” outsourcing remain out of sight.
Spotify conveniently has team product owners. If the client company wishes to stick to the “cost-saving” outsourcing model of the 90s, where the rest of the team is far off and programmers change constantly, you don’t have to make the hard decision of starting to insource developers.
Transformation as a big bang project. In the “Spotify model” you don’t have the notion of Kotter’s (and SAFe’s) dual operating system and is no recommendation of doing the change by moving people group by group into a “parallel organization” which operates in the new way.
From the perspective of the business model of the big consultancies, the above mentioned factors play well together. Further, as it’s not good business to sell a small incremental solution,- big consultancies invariably provide a big solution. The job then is to get in, do a quick transformation project with a big of a bang as possible, with as many consultants as possible (who possibly change constantly), with a clear beginning and an end from an internal resource and pipeline management perspective.
Indeed, most of the advice out there seems to point against a big bang or considering the transformation as a project. The intent of changing the way of working should concern and be clearly communicated to everyone, but rolling out the actual change (in other words, “moving to the parallel organization” as Kotter and subsequently Larman put it) should be done group by group, preferably starting with real, not fake volunteers. And you get real volunteers by educating everyone – something which is hard to do with a big bang.
Then, the fourth reason:
Why Spotify instead of LeSS? Big clients and big consultancies both favour big solutions, and LeSS certainly doesn’t look like one. It also doesn’t help that folks versed in LeSS do not typically work for a big consultancy, and instead quite clearly argue that such method vendors should be avoided.
Instead, LeSS folks strongly state that the solutions should come from inside the company.
Resources to help you on your way
As these things go, if you are still reading this, chances are you may not be one of the people who get to call the shots whether to “adopt Spotify” or not.
So, I’ve collected some curated materials below to help you on your way. I’ve listed them in the order of importance:
A reality check in the form of a video: not even Spotify uses the Spotify model – particularly not outside of R&D which I’ve heard being touted as an upside of “the spotify model” by the big consultancies. The linked video is by another co-author of the Spotify model, Joakim Sunden. An interesting detail is that Spotify nowadays has one manager per every five people.
This article by Alexey Krivitzky does a good job in analysing the Spotify model from the perspective of optimising for adaptiveness (in other words, agility), and thus, points ways forward to heights not directly supported by the model itself.
This video (Death of the Spotify Model) by Girjs Meijer and Marcin Pakulnici) seems to talk about the same story as the above article by Rowan Bunning. Essentially, the moral of the story seems to be dismantling the “entrepreneurship” and shifting all of the teams as general-purpose teams striving to work on the highest value.
“Never argue with a fool, onlookers may not be able to tell the difference” – Mark Twain
Back in the day as researchers we pushed Agilefant forward with a versatile-model-first approach. While it lacked bells and whistles such as attachments or detailed user access rights, it had the concepts needed to support large scale agile already in 2007.
Fast forward to today, its last and final incarnation was known as Nektion (the proliferation of the A-word tends to repel executives whose organizations might need it the most), and its entire ontology could be configured to fit the convoluted structures of large complex organizations you might run across.
Despite that, or perhaps because of it, I nowadays find myself rather agnostic with respect to whether agile should be scaled using frameworks such as SAFe, LeSS or DAD – or if it should (or even could) be scaled at all. Anyway, the result is usually better – if only slightly – than the darkness which existed before trying “agile” out.
Still, many of the lean/agile thought leaders out there do have clear opinions on the matter. If you’re in the process of “scaling agile” or considering it, my advice is that you should explore these opinions, and consider how the views expressed may or may not apply to your context.
To help you get started, I put together a table of some of the writings around the topic from the better known writers of the field I’ve run into. They are ordered starting from the most recent.
Many of the posts I’ve raised are critical of frameworks for scaling agile. Some are even critical about the notion of scaling agile in the first place. I made this choice because the organizations and people who are in the business of providing frameworks, tools and consultancy for scaling agile already cover the upside quite well.
There are also other posts, but I’ve tried to condense this list to the most popular and/or such that they have some depth to them.
By exploring the material below, you’ll hopefully become aware of the tensions around the topic – and thus are better able to steer clear of the potential pitfalls in your own transformation efforts.
While some comments are nowadays outdated (for example the notion that “SAFe allows to release at the PI cadence”), all of the authors there are surely worth following, and to dig deeper, check out also the commentaries of the posts linked below. I’m updating (last updated 2024-05-31) the list as I find new noteworthy articles.
“…marketing stories. Some practitioners have been there and know the difference between marketing and real stories, others know not only how things started yet also how things are going now.”
“It’s not a coincidence that SAFe was created by the same person who made the Rational Unified Process (RUP). In my opinion, no buzzword (Agile, Scrum, Lean, Enterprise, etc.) can cover its true nature.”
“[…] viewing teams as a “delivery” function instead of a strategic one. The high level thinkers come up with ideas, and the low level doers execute on those ideas. Ignored is the possibility that those closest to the work might be best equipped to make decisions about it. […]”
Large organizations seeking agility […] cling to the faorganizations seeking agility […] cling to the familiarity of waterfall processes. SAFe gives the illusion of adopting agile while allowing familiar management processes to remain intact.”
“[…] I’ve struggled with it for a long time. […] Believe me, I’ve tried to understand, support, and apply it. […] But it’s too big, far from the principles of simplicity at the heart of agility [and] focused on pursuing revenue. […] Just because it’s popular, doesn’t make it right. Nor does it mean that I have to support it.”
“The cultural aspects […] are the overriding blocker to systems thinking. Merely talking about it briefly in a 2 day workshop is not going to overcome that challenge.”
“It encourages massive batching […], old world thinking on estimation […], doesn’t change leadership behaviours [ …], doesn’t force a change in organizational structure”
“There are very few people voicing the perspective of non-consultant full-timers. The narrative is primarily driven by consultants and “thought leaders”… all with […] vested interest in guiding the perception of the market, closing deals, and getting their foot in the enterprise door. […] Thoughtful comparisons of approaches would benefit everyone.”
“The emphasis […] is more on descaling big complex problems into small pieces than on scaling up the organization to match the complexity of the problems it is dealing with.”
“Suffice to say, I have a reasonable perspective on SAFe in real life, which I prefer to the typical theological debates that arise when SAFe is discussed.”
“Good consultation often helps to get results, also with SAFe. However, there is the risk that the systemic conditions are not changing, and the change remains superficial.”
“[Both LESS and SAFe use Nokia as a reference, but] LeSS was and is mostly used at Nokia Networks […] while SAFe was mostly used at Nokia Mobile Phones”
“[…] a huge fraction of the dependencies between teams are artificial. They are due to poor allocation of work from above, and to the existence of unnecessary silos of responsibility.”
“When teams are forced to use complicated taxonomies for their stories, they spend time worrying about whether a particular story is an epic, a saga or merely a headline.”
“The problem is NOT that we lack ways to scale agile. The problem is NOT that we fail with agile in large organizations. The problem is that we are large. […] The frameworks take “large scale” as given, and do very little to reduce that.”
“Rumi urges us not to become too attached to one “grain”; one teacher or one way, or, in our world, one agile framework or one perspective. I urge the same. Rather, let us look out wider and farther.”
“Release Train is an example of a remedial practice presented as an ultimate solution. […] SAFe does not push hard to eliminate the problem: it just gives a way to accommodate it.”
“in 2003 I decided to focus on […] reducing or eliminating resistance to change. A process-centric focus wasn’t working without a lot of money, positional power and fear to motivate individuals to fall into line.”
“The question is not whether SAFe should be used as the strategic basis for large Agile adoptions. The question is this: What will make those adoptions most successful?”
…” a horrible, money-making bastardisation […] of Scrum, Agile and Waterfall…”
P.S. Curiously enough, I was not able to find posts of sufficient depth, quality or otherwise of interest (subjectively, of course) from 2016. But surely there are some lying around! Can you point me to any?
So you still, even after all this time, need to use Jira in your SAFe-going organization? Or are you using Trello? Or any other tool (even if it’s a wall and some post-its) that has “workflow” as a big the visible key element? There may be a better way of leveraging it, read on…
““Get rhythm when you get the blues” – Johnny Cash (Photo by Matthijs Smit on Unsplash)
This post is a continuation and refinement of the series where I’ve examined simpler ways of using Jira to run a SAFe-like model (see the 2020 version and the 2018 version). They also explain the problematics of using Jira to run SAFe in detail.
Re-examining this topic was spurred both two things: by the good experiences I’ve had applying the model at my current employer, DNA, and a recent page of (IMO bad) workarounds to run SAFe with Jira put together by ALM Works (the creators of e.g. Jira Structure).
Everything I wrote about in the 2020 version regarding issue types, number of boards and progress metrics still applies here, so I’ll head right into the “new” juicy bit: the planning cadence based workflow – as opposed less-than-optimal barrel-riding the waterfall type workflows you tend to encounter in the wild.
Let’s start with the latter
Riding the waterfall in the barrel workflows
Often, the workflows you see in your local Jira resemble something like this:
It is an example workflow from SAFe that’s been around since SAFe 3.0 (I think). For the above pic, I’ve combined the portfolio and the program kanban workflows from SAFe 5.1. There’ the stages have clear definitions.
But when you encounter it in the wild, the definitions of the various stages may be or may not be documented somewhere in the depths of the local Confluence. If they are, theytypically have been written years ago by SAFe-consultants who have already left the building.
But at least you can be sure that everyone – even the teams aboard the same “agile release train” using the board tend to understand the stages in their own special ways. As a result, it’s hard to assess whether the work items are actually up-to-date – and even if they weren’t, even less guidance on where they should reside.
Also take note of the embedded stage-gate and waterfall flavors in the model.
Another, even more common workflow you see out there is something like this:
In the teams and multi-team settings I’ve coached during the past few years, I have come to suggest a workflow which is based on the planning cadence the team or organization strives to adhere to.
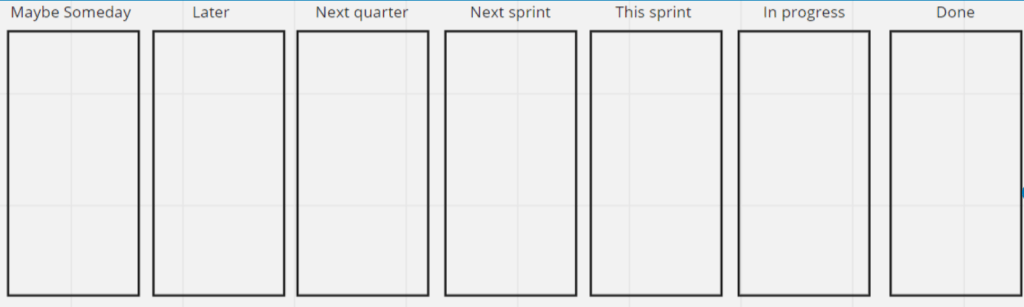
Here is an example of a such a workflow devised as the starting point for a multi-team Scrum organization; the columns before This sprint represent (their best guess at) the roadmap, while the columns to the right of it represent the contents and status of the ongoing sprint.
While sometimes this kind of worklow at first raises eyebrows and even the occasional WTF from even those who are really agile savvy, I’ve yet to meet people who have tried it out in practice and want to go back.
The rumour has it that in the Fall of 2021, even the highly skilled agile coaches at Nitor Delta adopted this style of workflow to manage their operational work as one of them had seen it work at DNA.
As this approach at designing the workflow seems at first to be a bit out-of-the box, I know I’m bound to encounter some setbacks. The level of transparency – and the requirements for splitting work and keeping the items up to date – admittedly can be too much for some situations. But at the time of writing this, such setbacks have not yet happened.
Note, that all the work items – be it Epics, Features, Stories, Sub-tasks, Bugs – whatever you have, are using exactly the same workflow. As in my previous Jira usage posts, you use quick filters to see what work items you’re interested in (you can even devise filters to see all the items under a particular Epic or sets of Epics), and in a similar matter, separate teams by using labels and quick filters.
The first question that people usually have how does one interpret putting an Epic into a particular column. That denotes when we expect it to be ready. For example, an Epic might reside in the Next quarter column – that is when we believe it would be ready – and all the while Stories from it are being worked on in this sprint, the next sprint and so on. Or, if we believe a Feature is supposed to be ready for release during this Sprint, it can go into the Sprint level columns. And as with my previous posts, there’s no need to use Jira’s rather convoluted and glued-on sprint functionality.
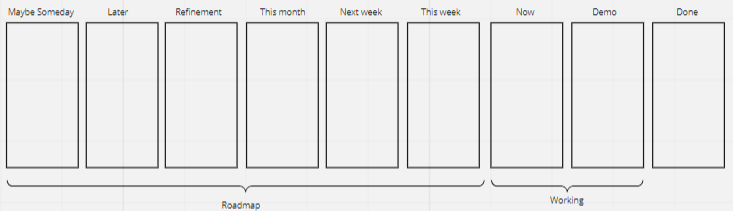
Here’s another example, used by a multi-team team organization working without a sprint cadence:
As there are no sprints, the teams use the Month and Week slots to plan their near term future. They even have a “now” column to help visualize and plan what each of them is actually working on right now.
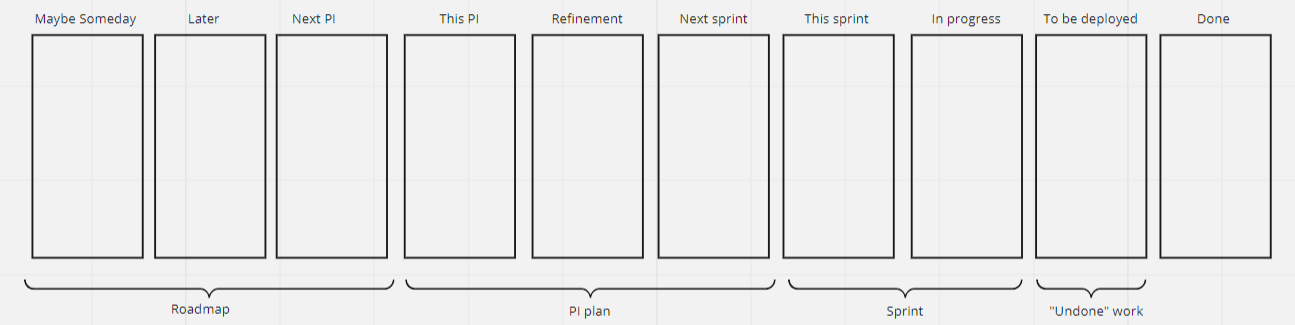
Then, an example workflow built in the style of SAFe :
Here, we have the Next PI and This PI columns to denote the roadmap and the current plan. Newly added work items go to the Refinement column. That column should be kept empty, and as items come, it is decided where they should go to. A critical bug could go directly into the sprint and the top of the In progress column, while some discovered enhancements or important business hypotheses to be tested might go to some of the left-hand columns.
In this example, the deployment decision is something this particular agile release train cannot do it on its own, and thus that stage is not considered a part of the sprint, but rather “undone work” (a concept from LeSS that SAFe also has since then adopted).
Frequently asked questions
Every now and then, when people I work with encounter this rather unorthodox way of laying out the Jira workflow, they have questions regarding how does this model handle the things they were used to do with their previous, waterfallish workflow.
I’ve collected some questions and answers below, and will keep updating them as I run into them.
Q: How can we know whether an Epic will be completed and which column should it go to? Well, it’s an Epic, so you can’t know. But you can guess: put it to the column that you think best fits. Could be the next PI, later, or maybe someday. The aim is to communicate your guess to other parties, and the possible hard questions that follow may help you define and split the items further.
Q: If you’re using only a single board for many teams, how can the teams see and plan only their own work? Label the work per team (apply more labels if more teams are responsible) and use quick filter. And anyway, Jira doesn’t support the concept of the team, so with any workflow you’ll have to tackle this somehow.
Q: Will the board be really slow as it contains all the work items from all the teams? Yes, the board does get slower with really many items. But in my experience it will not get too slow (compared to the general sluggishness of Jira).
Q: Surely, bugs will need a different workflow? Well, fixing bugs is work, just like your stories and features. So far I’ve seen no good reasons to model the life of bugs any differently. In my opinion, the decisions when to fix which bugs are spelled out in this model rather clearly.
Q: Surely, we will need more columns to denote how the work proceeds inside a sprint? And if we add them, there will be really many columns. Certainly, if your team does not work as a team, and work gets passed around from analysts to coders to testers, additional steps to just In progress will prove useful. You can either model these things as sub-tasks, or then just add the columns. In one setting I encountered we ended up adding development, ready for integration testing, integration testing, and acceptance testing as separate columns, as the matureness of the organization in question needed it. But still, a clear win is that here, these all meant to happen and get done inside a single sprint.
Q: In our stage-gate model, we have a phase where we get a formal sign-off from the customer that the requirements are OK and we can proceed with design and development. How do you handle it in this model? My suggestion is to create sub-tasks (e.g. Signoff with customer) for such things to leave the trace. I guess I don’t have to find you references that formal sign-offs such as these can be a sign of dysfunction. Customer collaboration over contract sign-offs and so on.
Q: It’s really hard to use the columns beyond This month, as we need to split the items so small. Learning to split the work into end to end slices is hard. But gets easier as you are forced to practice it applying this model.
Q: We are using the Xray plugin for supporting quality assurance; surely the Test Plan, Test Set, Test and Test Execution will need a different workflow? This is more complicated than most of the questions I’ve run into.
As a side note, with my history as a recovering tool vendor, I find myself questioning whether XRay is some form of specialists-cementing-their-importance-and/or-separation-of-concerns (as opposed to going for fast-paced close collaboration where everyone has the title of ‘team member’) with additional tooling. Does XRay just adds buttons, knobs and other moving parts of questionable usefulness, with the the spirit of the waterfall being ever watchful…
Test Plan: Defines what tests should be executed for what version
Test Set: A group of tests, for example all tests related to some application functionality. One test can belong to multiple test sets.
Test: A test case and it includes test steps, actions and expected results from those
Test execution: Represents a single execution of the test. Test executions can be created directly via Jenkins integration
Clearly, executing tests is work. If we are doing that in this sprint, they would go there; if in the next sprint, they would go there. Designing tests, test sets and test plans is work as well, so I can’t see a reason it could not be handled just like any other work.
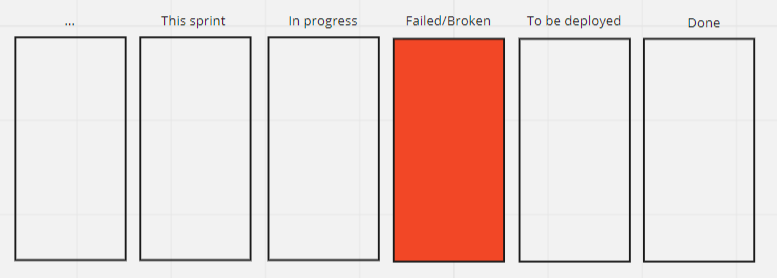
However, one case I see where an additional workflow step could be warranted is in creating more visibility into the the case of tests which fail. While putting a failed test into a done column would clearly not work, some visibility could be lost by returning it into a previous step as well.
This might be resolved by adding a column inside a sprint: something along the lines of Failed / Could not test / Broken. If a test is failed, it goes into that column. If a Story is found broken, it will go to that column. Like this:
For fixing, the the Story goes back into the This sprint column, along with the failed tests, and the cycle repeats until either the test is passed (and is Done), or it is decided that the Story is postponed.
Now, I have not used XRay in practice, so I’ll return to this after further discussing with the experts who were interested in this question.
EDIT: in the end, we decided to omit the XRay items from the common board, and put a separate board for them, with a different flow. They were just “too different”.
Starting a new job as an agile & devops coach, I looked for gurus to tell me what devops means. Turns out it means what agile originally meant. Here is a curated selection of some of the best talks on devops I could find on Youtube.
“There’s a lot of fake news about DevOps out there” – Jamie Edwards
Perhaps it was the new normal of Spring 2020. Or perhaps it was working as part of a lean-agile tower-of-power assessing the agile maturity of component groups in a global corporation’s IT department.
Whatever the reason, I started yearning for a bit more technical role to satisfy my inner nerd also during the workdays.
After all, absolutely the most kicks during the recent years I had gotten was from tinkering ETLs to get Tableau visualizations out of a financial company’s big-ish Jira instance. While I’m not the right person to assess whether it in the end was useful, it surely was a ton of fun!
And could such a bit-more-technical role perhaps be found in an engagement the length of which would not be swayed so easily by the whims of the yearly rounds of budgeting?
Having spent over 20 years in different external-type of positions – applied research, tool-vendor-entrepreneur and consultant – I also realized there’s at least one more role which I had yet to experience. The coveted position of an actual employee in at least a medium-sized, but preferably, a large corporation!
So I started looking for a new job, and with the help of some people I had tried to sell Agilefant to back in the day, found what I was looking for: an agile & devops coach at DNA!
So what is “devops” anyway?
As an avid computer user since the mid-eighties and a SaaS software entrepreneur I certainly had a grasp at what devops was about. Certainly it was not about setting up devops teams. And while according to one of my favorite agile gurus Craig Larman devops essentially means the elimination of the operations department, I wanted get a bit more three-dimensional picture of the key things from other gurus as well.
So I reached out to Youtube and started listening. And at the end of this post you can find a hand-picked selection of those eight presentations I found most useful.
The final spark to get this list out in the open was when I yesterday saw one of my old friends, the magnificent Timo Ralli, getting promoted to the role of Head of Devops at Visma.
Perhaps after ten years we both will be even bigger gurus in the matter – but for now it’s probably useful to listen what the current gurus have to say.
And I certainly am hoping that this blog post can also serve as a some pointers for my colleagues at DNA to get an idea of the angle I’m looking at what we will be working to solve together.
Enjoy!
P.S. I’ll be updating this list as I run into new good stuff; last updated 2021-01-08
The strange days of 2020 sprung me into a nostalgy-filled run through the AD&D Gold Box games with a stats-fairly-rolled, non-cheating group of adventurers. Here’s a recollection of how I did the unthinkable – winning the “impossible battle” of the 2nd game of the series, Curse of the Azure Bonds – without the Dust of Disappearance. I understand if that does not ring a bell for you.
“Being a Saurial paladin, it’s my duty to teach those who designed her hauberk a thing or two” – Dragonbait
To gamers born in the 70s and 80s, the AD&D Gold Box series is a game equivalent of Star Wars (IV, V, VI) or the Lord of the Rings (the book).
Kicking off with Pool of Radiance in 1988, continuing with the Curse of the Azure Bonds in 1989, and ending with some 20 games in total, the series offers hundreds – ok, thousands of hours of gameplay.
By today’s standards, most of that gameplay can be considered – putting it politely – tedious. You just can’t kill em all using in-game-purchases which pappa betalar. But at the time they appeared, the gold box series games were – in a good way – revolutionary in many aspects.
The games are also quite difficult. At least to those not what well versed in the Advanced Dungeons and Dragons 2nd edition’s intricate set of rules, which the games were impressively orthodox in following.
And even to those versed in the art, there were some encounters in the games that posed real challenges. Probably the most well-known – and arguably, the most difficult of all of them – was the optional fight against the Mulmaster Beholder Corps in the Tower of Onyx in Curse of the Azure Bonds. Yes, it is more difficult than Dave’s Challenges in the later games.
Before you read on, a fair warning – I’ve also ascended in Nethack – but only once, and that was in the mid-90’s right before sex, drugs and software engineering diverted me off course for several decades.
The Mulmaster Beholder Corps
Being a tongue-in-cheek encounter by the game designers, in the fight your party of up to six characters are facing a total of 14 beholders, 10 dark elf lords, 10 high priests, and 10 rakshasas.
As comparison, the boss battles elsewhere in the game feature for example sport a single beholder (with a host of lackeys of course), a single dark elf lord, and, well, way less high priests and rakshasas than those thrown into this battle. Oh, there’s also the host of black dragons at the top of a tower, which I out of luck sweeped through at a first try this time around.
The party
Here’s the party I went into the battle with:
The characters are all half-elven for two reasons. First, this allows the use of haste whenever needed; no dying of old age (that actually happens with humans, I tested it back in the 90’s). Also, half-elves are the only class which can be a triple-multiclass fighter/cleric/mage.
I did not use elven folk as they cannot be raised from the dead; I actually raise dead characters as needed so that they drop a point of constitution and lose some hit points – again, making things a bit more balanced for the monsters’ sake.
Note, that I did cheat here a bit. Using Gold Box Companion I disregarded the level-up limitations of half-elves (being 5 cleric, and 8 for fighters and mages). However, if I had known that blessed crossbow bolts insta-kill Rakshasas, that might offset the lower levels. I guess I’ll have to try that at another time.
The monsters rejoice for the party has been destroyed
A typical winning strategy in these games is to decimate the enemy with enough well-placed fireballs and stinking clouds. However, in this battle, both the beholders and rakshasas are completely immune to magic, and the dark elf lords, besides having quite good saving throws, simply shrug off 50% the spells thrown at them.
Now, suppose that I’d send my party (see below) with the usual buffs into the encounter?
Here’s a short video screen capture of what happens when you approach the fight with the typical strategy – even with all the buffs (like bless, prayer, haste, whatnot).
This was the situation after the first combat round: my party has been pretty much decimated, with not even a single enemy killed.
The “supposed” way to win this battle is to use a special item a that can be found early on in the game: the Dust of Disappearance. It renders the party with improved invisibility for the duration of the battle: in other words, the invisibility will not disappear upon action such as attacking or casting spells. Thus, the enemies simply stand still and wait to be hacked to bits and pieces one by one. Even the rakshasas and dark elf lords, who otherwise see invisible, will not see the characters.
And even with the Dust, the battle will be long and requires careful playing, as in the melee range the dark elf lords will deal hard blows at your invisible characters with their +5 long swords and two attacks per round.
This time around (and some 30 years after my first tries), I decided to give a go at winning the battle without the dust of disappearance. I also had handicapped myself by fairly rolling the characters’ stats (in the game, you can modify them all to the maximum upon character creation).
This handicapping was quite intentional, as by having some 35 years of experience in mastering AD&D rules, I wanted to try my best to keep the games challenging. Being overpowered is so totally boring.
Other attempts
There are folks on the Internet who claim to have won the battle without the Dust of Disappearance. However, looking at their gameplay videos, it can be discerned that various things which I consider cheating have been employed. To name a few, the characters’ hit points have been edited to 200+, the best items have been duplicated to all the characters, and the characters’ stats have been modified to the maximum.
To make it a fair fight (and being a bit of a perfectionist), I decided to forego such shortcuts.
Know your enemy
I spent roughly a week of calendar time trying out different tactics and getting to understand the enemy. This is what I learned.
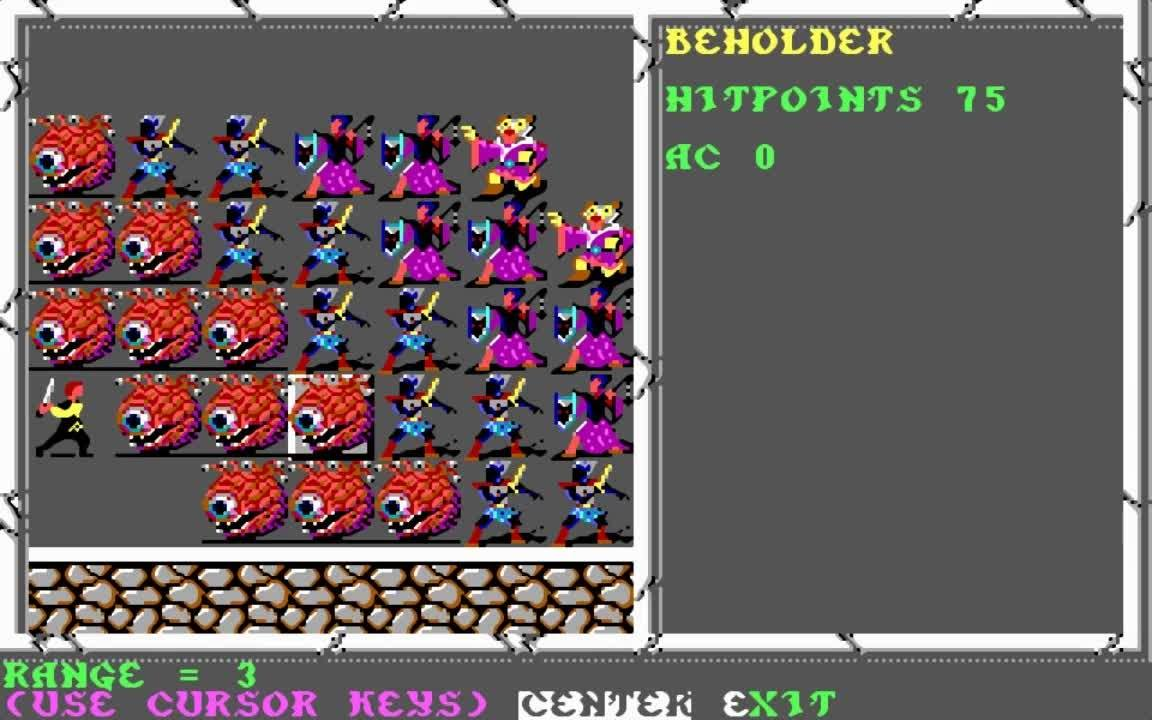
Beholders
These 75hp buggers are totally immune to magic, the only thing that can hurt them is physical damage. With an AC 0, they’re fairly easy to hit, and take damage from non-magical weapons.
The most important thing to know is that at range 7 and beyond, the dreaded beholders are totally harmless. At range 4-6, they cast sleep – which can’t do anything for your above level 4 characters – fear as well as slow, which can be quite disaster for your tactics, and cause serious wounds.
At range three, the real fun begins: in a single round, a single beholder can cast disintegration, flesh to stone and (perhaps, not sure of this) slay living rays at you, and unless you’re really lucky with your saving throws, that’s game over for that character, at least for the ongoing fight.
However, beholders cannot target invisible or blinked-out characters. Also, beyond a range of 6, they can’t do anything except move towards you with 3 steps per round. And they can move after they cast their magic, but not the other way around.
This cast-before-move-but-not-move-then-cast goes for all the critters in the game as well – here, the high priests and the rakshasas. I read it online that the computer AI learned to do that only in Pools of Darkness (don’t know how that was for the Krynn or Savage Frontier series)
Rakshasas
Rakshasas also immune to all magic, but with 35 hit points and an AC of -4, it is quite possible to put one down in a single combat round with a concentrated attack. However, you need a magical weapon to do damage, so you’ll be needing the +1 arrows that you can purchase from the Dagger Falls magic shop. They’re also fast, with a movement of 15.
What is problematic, however, is that Rakshasas can see and target invisible characters and cast lightning bolts at them (however, the Dust of Disappearance would for some reason prevent this as well). While they cannot target blinked-out characters, blinked-out characters will take damage from a lightning bolt thrown at somebody else.
The range that a lightning bolt can be cast to is max 10 squares. This means that at the start of the combat, all of the rakshasas can target at least one of your characters. So if you don’t take steps back, you’ll have a maximum of 10 bolts of level 7 (that’s 7d6 damage, half if you make your save) thrown at you.
So, suppose that you successfully roll half of your saving throws, that’s 5 x 7d6 / 2 + 5 x 7d6 = some 150 hp of damage in total per round, and since a single lightning bolt can damage multiple characters and bounce back from the walls to deal more damage…
There are a couple of items in the game that halve the damage from electricity, but no spells to counter electrical damage.
The conclusion is that if you stay within a 10 square range, the rakshasas alone could kill your entire party in the first round.
Dark elf lords
These badasses have a movement of 24, an AC of -7, 108 hit points, strike twice per round with their +5 long swords and have a THAC0 low enough to hit your characters often enough to make you cry. With their infrared vision they can see invisible characters well enough to rush at them.
With a head-to-head, blow-for-blow physical combat with all the buffs for your party, you’d be sure to lose to a group of 10 dark elf lords.
High priests
Last and the least, the 60-hp high priests. Sure, they cast hold person and slay living, but as they are susceptible to fireballs, my party could in principle obliterate them in some 3 rounds without taking anything back except an occasional swing from a +2 flail.
One could probably even remove from the high priests from the fight altogether without affecting the overall difficulty that much.
Throwing caution to the wind
The bigger picture for the fight is shown in the post-it below:
As you’ve probably guessed at this point, head-to-head tactics will not work in this one. Luckily, there are two places in the battlefield where you can escape the onslaught. These are shown in the picture below:
In the northwest, there is a corridor which after a while turns around the corner to the east. And in the south, there is a long corridor to the east with a 4 square wide tunnel.
The monsters’ pathfinding AI will try to approach you along a straight line. So, if your characters are behind a wall, they’ll just get stuck to dancing on the other side and will not go out of their way to circle around to get at you. I chose the south tunnel as my refuge, but in principle, the northwest corridor could also work.
The problem is that from behind a wall you can’t get to the monsters either, so something special was needed.
Note: I discovered that the game has a timeout for fights; after enough rounds have passed – I don’t know how many, it could be the max number from the 8-bit game engine, in other words 256 minus one – that is at least the maximum for character hit points or arrows in a single stack), the fight will end and the computer will determine that you won.
So basically, you could just run to the tunnel and wait until you simply win. While that of course would not suffice for me, I “discovered” the timeout in one of my lengthy tries during the passion week… so that’s added difficulty, try to kill em all without hitting the timeout!
Pre-combat preparations and the first round
In preparation for the fight, I stacked up on +1 arrows (255 for each character) and mage scrolls of blink, haste and lightning bolt – you can get these from the magic shop. Not having to leave space for blink or haste, you can memorize lots of fireballs…
The #1 crucial question is to how to get past the first round to the safety of the tunnel. With luck and lots of tries, I managed at best to get 5 characters out of 6 to survive the first round by immediately heading towards safety.
But then I remembered the spell Invisibility 10’. So, before the fight I cast no other buffs, just that, and then head towards the tunnel. You might get struck by a dark elf lord or two, and if you’re unlucky, a rakshasa might throw a lightning bolt at you, but you’ll survive.
Once you are behind the wall delay until all the monsters have moved. At that point, cast all the buffs – haste, bless, prayer, and the like. You might also want cast blinks, but that’s less important at this point.
The bombing runs
So it’s round #2. You’re behind the wall, all buffed. The monsters can’t get at you, and you can’t get at them.
Move eastward so that the monsters AI will move them away from the tunnel entrance. Especially the faster dark elf lords and the rakshasas will get packed into a corner at the southeast of the room they start in, like this:
Now it’s round #3, and the time for bombing rounds! Delay until all the monsters have moved, and then move out of the tunnel to face the monsters. The bombing rounds, I think, were for me the key to winning this battle.
Have 5 party members to cast fireballs (prioritise targeting as many of the dark elfs as possible, any additional high priests in the area are bonus), and the 6th party member to cast invisibility 10’ to end the round, so you’ll arrive to round #4 all invisible.
When you get your turn on round #4, move back to the tunnel, stay near the entrance, and delay until all the monsters have moved. A couple of dark elves might rush at you (they see invisible), so be sure to have the character with the best armor class and a wand of fireballs stay a couple of steps from the rest of the party there to take these blows; this character should also have the ring of invisibility, protection from evil, and the best AC of your group. Blink and a minor globe of invulnerability to protect against the lightning bolts will not hurt either (though most of the rakshasas are beyond their range at this point).
If you have blink in place, that character should have the wand of fireballs and use that as soon as he/she get’s the chance; if you cast a fireball as a spell, you are vulnerable to the beholders during the casting time.
Arwen is blocking the dark elves from going after the other characters
At the end of the round, the rest of the group will move back to the open, cast again 5 fireballs, and top that off with another invisibility 10’.
The main goal of these bombing runs will be to weaken the dark elf lords so they can be beaten in melee without a lengthy blow-for-blow. Sure, they will shrug off 50% of each fireball due to their magic resistance, but some will get through. With 5 10-level fireballs, that’s 5 * 10d6 = 5 * 35 (on the average) = 175 hp of damage, halve that with the magic resistance ~ 90hp, reduce that with ~50% successful saving throws… on the average, the dark elves will take some 45hp of damage per bombing round. With three bombing runs, a third will be killed outright, another third will get some serious damage, and a couple will escape damage altogether.
As a side effect, all the high priests will die as well.
These bombing runs can can be repeated as many times as you have invisibility 10’ at your disposal. Of course, each invisibility 10’ reduces your fireball capacity by one, as they both are 3rd level mage spells. I used three of them.
Eliminating the remaining dark elves
Stay near the beginning of the tunnel with your blinking, invisibility ring-equipped character up front. If there are dark elves in melee range, concentrate attacks on them. If not, have the invisibility ring -character use the wand of fireballs on the dark elves within range. Feel free to have the rest throw in all mass area spells (fireballs, ice storms, wands, necklace of missiles and so on) for extra damage.
Some rakshasas will also wander to face you, and if many come, it’s best to have all but the invisible, blinking character back way east of the tunnel to stay out of the lightning bolts’ range. The frontline person can cast a minor globe of invulnerability to have the lightning bolts that get cast be in vain. When in melee, the rakshasas will not cast lightning bolts at all.
Keep focusing on the dark elves, ignore the rakshasas unless there are no dark elves to target at.
Killing off the remaining rakshasas
Once all dark elves are gone, there will probably still be some rakshasas left. Lure them into the tunnel with a character who has a minor globe of invulnerability on. Kill them off with ranged weapons and melee attacks.
Using the beholders as target practice
Once all the rakshasas are gone, it’s time to get to the beholders. One or two might have wandered into the tunnel earlier (you’ll actually see I had a bit of trouble with that in the video during the dark elf killing stage) and gotten killed, but most will be intact.
Haste your characters, and move them into the open. Use ranged weapons, and kill the beholders one by one. Delay until the end of the round before shooting to make sure you always are at least 7 steps away when the beholders get their turn to move; your superior movement will make this entirely possible. Repeat until all of the beholders are dead.
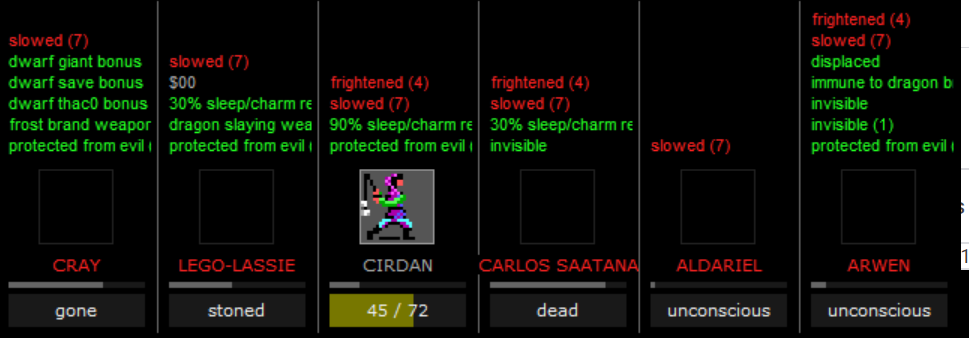
From the videos below you’ll see I had a bit of fumbles while killing the beholders, those cost the life of Lego-Lassie.
So you still want to use Jira in your SAFe-going organization? Here’s another, an even simpler way to do it.
– Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius, and a lot of courage to move in the opposite direction
– E.F. Schumacher
Back in May 2018, I posted about the The simplest way to run SAFe with Jira. After that, I’ve at clients as well as in attending other Jira-spouting companies’ breakfast seminars run into more set-ups which attempt the same – some better, some worse, but definitely more complicated.
Now, I don’t here intend to go into the details of why you would want to run SAFe with Jira and the fundamental challenges which lie in that direction – these are quite thoroughly described in my previous post.
But alas, there is an even simpler way to run SAFe with Jira, which may be too obvious to notice at first.
Confusion in the plugin land
I’ve had the set-up described below in my mind for some time already, but it took something I read this very morning on the ALMWorks’ Structure for Cloud Google discussion group which got me sparked about returning to the topic.
This is what I saw:
[Structure’s] customers split into two camps to deal with the discrepancy of how Jira does things and how SAFe prescribes it.
Some customers adapt the wording in their process to adapt to Jira’s […] They reason that a feature by any other name, is still a feature. […] They also work diligently to make sure everyone knows that instead of Epic -> Feature -> Story, their hierarchy is […].
A more common case is to adapt Jira to [match SAFe’s terminology]. They will link their Epics to Features and have Features link to Stories. They will define a specific issue link that reflects this relationship and will not use Jira’s built-in Jira of Stories under Epics. For example, they will use an issue link called “Implements”, so in their hierarchy, an Epic is implemented by Features, and in turn Features in implemented by Stories.
Now, as you might have guessed, I don’t recommend either of these approaches. There are simpler set-ups.
Another Simplest Way – The SuperVanilla
This set-up – let’s call it “SuperVanilla” is so obvious that was bound to be overlooked. Let’s walk through how to set up in terms of issue types, workflows, boards and progress metrics.
The set-up is such that for each SAFe portfolio, you can create a separate project using the steps below. However, do first consider whether you really have many separate portfolios as defined in SAFe – in all but the very largest of companies, you really don’t.
I also don’t suggest that you’d take this model as the prescription you follow until the end of time. What I definitely am saying is that only start complicating things when you are really, persistently, in pain without doing so.
Also, if you have teams which prefer their own way of keeping track of their Sprint level work, I would not impose Jira on them. What matters is keeping the Features’ progress up to date.
Furthermore, since in this set-up everything is in the same Jira project, if you want to restrict the visibility of certain issues, you can apply issue-level security. But I would not suggest going that way either.
OK, let’s get started!
Issue types
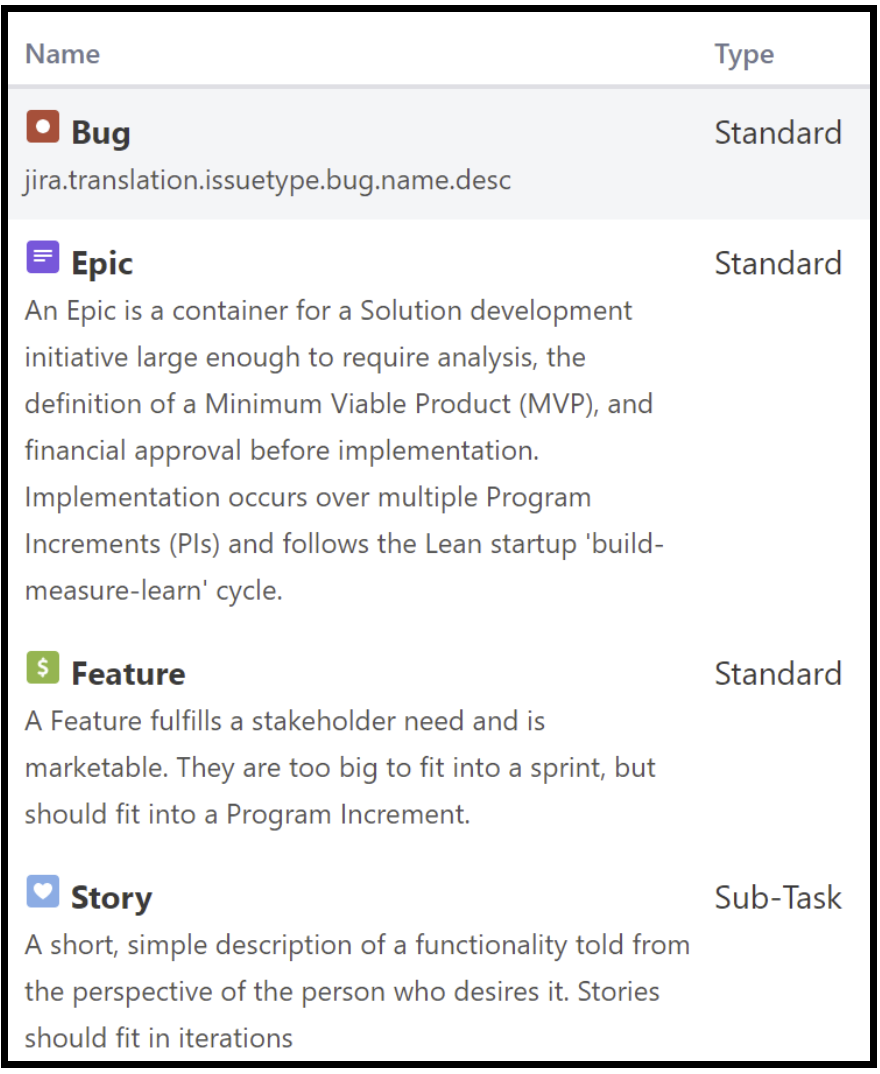
SAFe has a three-level hierarchy of Epics, Features and Stories. Never mind here the special terms they’ve cooked up for “Epics that can be completed by a single program / a single value stream”.
Jira, too, has a three-level hierachy – at least sort of – Epics, Stories and Sub-tasks.
I usually recommend to keep Bug as a separate issue type.
Workflows
Then, let’s look at the workflow configurations. Here, I’ve gone with the simplest solution that could possibly work – the same workflow for all issue types:
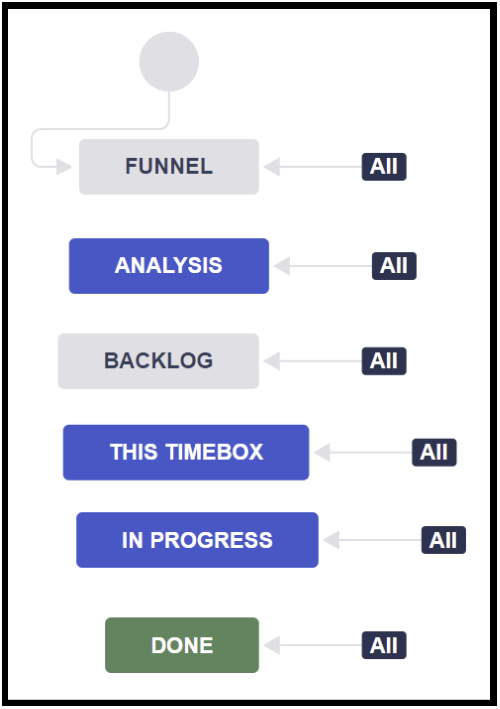
FUNNEL for ‘everything that comes up’, BACKLOG for things which are understood well-enough so that we can work on them, and an ANALYSIS stage to separate those.
Program Increments (PI) are modeled using the states THIS TIMEBOX and IN PROGRESS. Those Features which are in a PI which yet have no stories ongoing are in the THIS TIMEBOX stage, while those which have work ongoing are in the IN PROGRESS stage.
Another thing to consider – which I have not added here for the sake of simplicity – is that you will want to have a REJECTED stage to keep FUNNEL clean and to a manageable size.
Boards
The simplest solution is of course to use a single Jira Kanban board. Don’t use a Scrum board – Jira’s sprint functionality is very much glued-on-afterwards and thus rather convoluted. Definitely, it will not make things simpler.
And furthermore, with set-up there is no need to use Jira’s sprint functionality it at all.
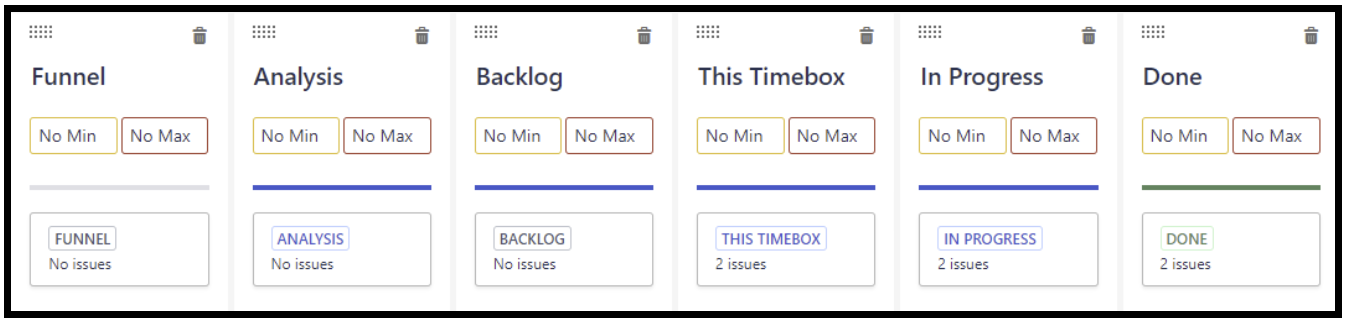
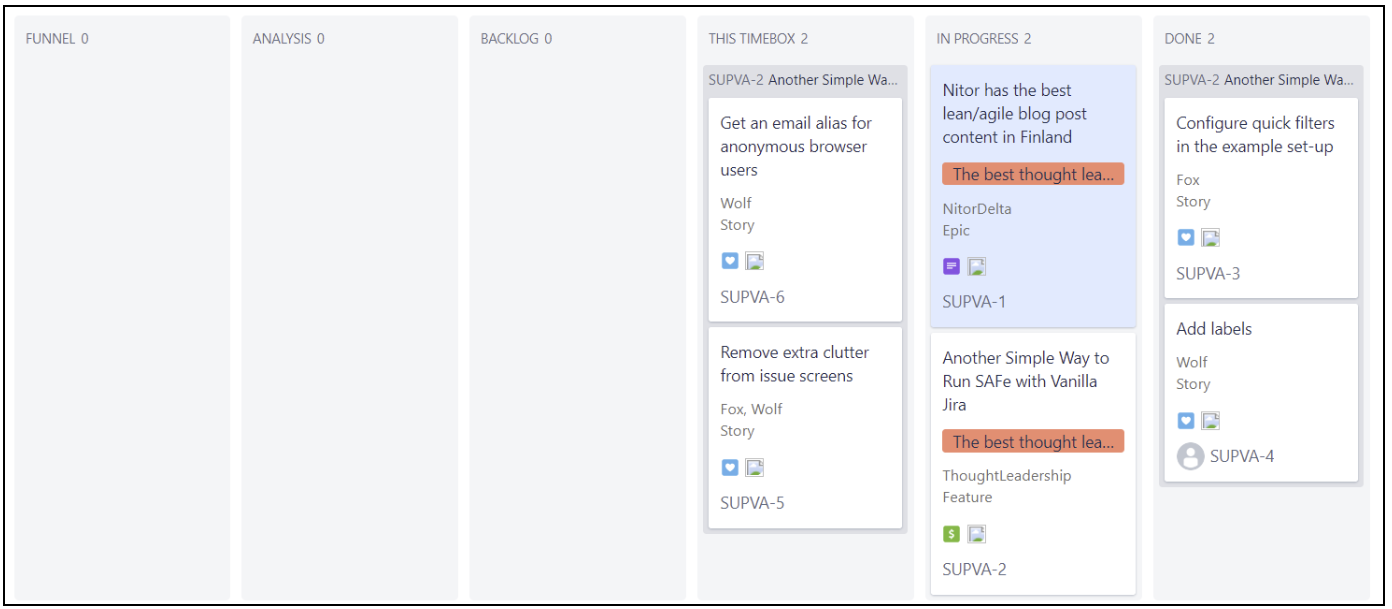
The first step there is to set up columns that match the workflow. The result will look like this:
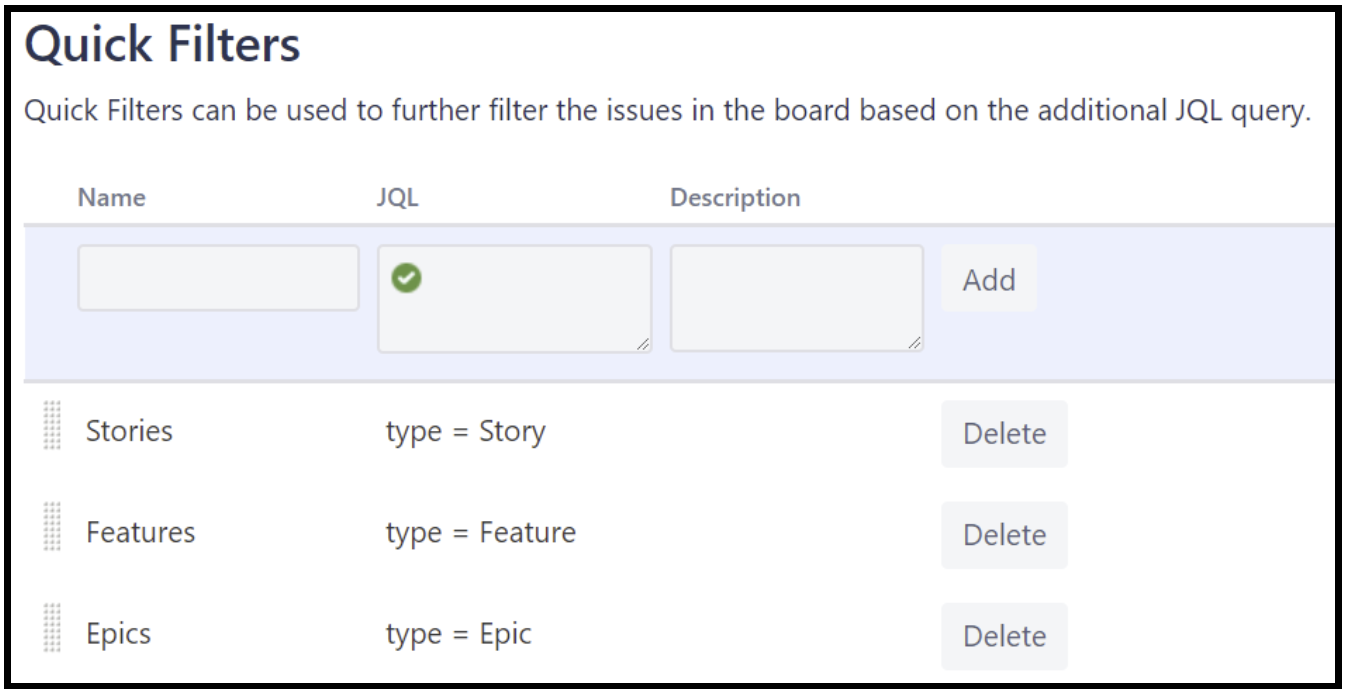
The general filter simply looks up all the issues in the project. On top of that, we create three quick filters to discern between Epics, Features, Stories and Bugs. Here are the filters for the three first mentioned, doing the Bug filter is left as an exercise for the reader:
Teams and trains
In addition, since all the teams’ work is in a single project, we need some way to discern and possibly also filter what issues – if any, belong to which team and train.
I discourage using components to denote teams or trains – those are best used to model – surprise – components.
Also, using a single login to denote an entire team like I suggested in my previous post is both forbidden as well as a tad too radical for most organizations.
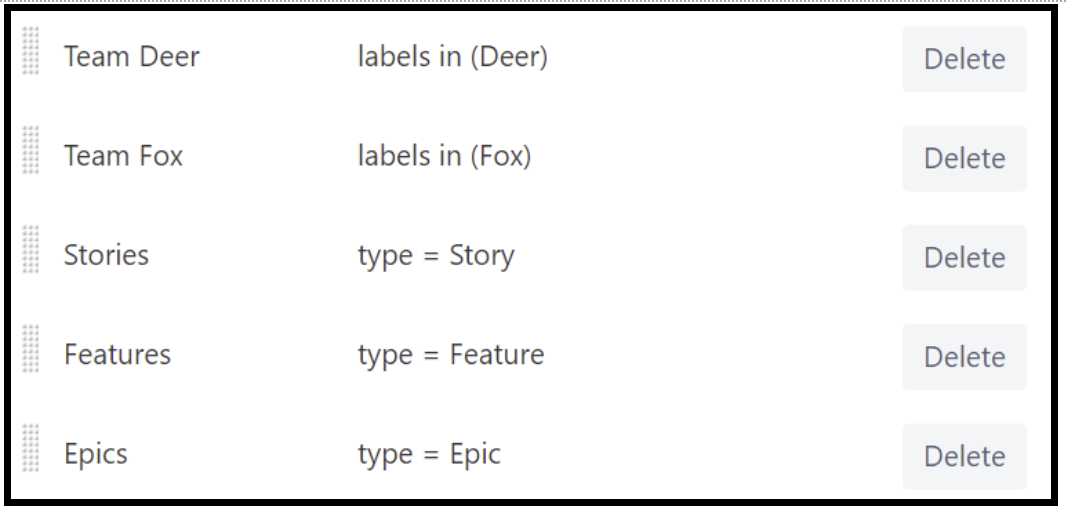
While we could configure groups to denote different teams, using labels is the simplest route to take. They can easily be seen on virtually any Jira screen and are quite easy to use.
In the case when there are several teams (or trains) who need to collaborate on a story, applying several labels is easy, and using labels can also be applied when there are multiple trains who work on the same solution. So, now we have the following quick filters:
And the board itself looks like this; just use different filters to look up only those items you are interested in.
Progress metrics
The most obvious metric you might want to have is to follow an Epic’s progress over time. To make that possible, create another quick filter which looks up the Epic’s Features using the following JQL
“Epic Link” = [issue key of the Epic] AND type = Feature
Note, that without the type limitation, the query will also bring up also the Stories under the Feature – which we do not want.
Then, look up the cumulative flow diagram, and apply the quick filter. Since Jira’s cumulative flow diagram counts the issues and does not weigh them with e.g. story points, it’s best to strive for Features of a uniform size. But then again, that’s what you should pursue anyhow.
While you have to a quick filter for each individual Epic whose progress you wish to monitor, the configuration is not a huge effort. You probably don’t have that many Epics simultaneously launching – or if you do, looking up a particular Epic’s progress is not your most pressing problem.
Anyhow, once you’ve created the first one, it’s a simple copy-paste operation in the quick filters where you simply replace the key of the Epic.
Looking up a Feature’s progress is also fairly straightforward – look up the related stories directly from the Feature itself, and discuss with the team(s) involved. Since Features should not span that long, there is probably not a need for explicit progress tracking as a function of time.
But, if you want to, the steps to create a progress metric for Features are exactly the same as for Epics.
As for Sprint burn-ups, pick your team, filter based on label, look up the cumulative flow diagram and there you have it.
Anything else?
So there you have it – possibly the simplest possible way to run SAFe with Plain Vanilla Jira. If you think I have overlooked something important, feel free to drop me a note and I’ll try to accommodate it.
As 2020 has begun, it’s time to reflect on what we’ve learned during the past 21 years of the things we today call lean and agile.
Like at the end of 2017, I’ve compiled a top list of lean and agile presentations which to me have been especially intriguing and inspiring.
The presentations are not in any particular order. Also note, that the presentations have not necessarily been published during 2019 – I’ve just run across them during the past year.
Nowadays most of us have a lot more ear-time than reading time. So just don your headphones and dig in, whether you’re commuting, doing the dishes or something else where your intellect could use a little simulation.
“The number of possible states in a C program with six 32-bit integers is bigger than the number of atoms on the planet. What about Javascript? Don’t ask.”
“Every 6 months in a performance review you have to show what impact you as an individual made. While that might work for a startup, for facebook, incentive schemes which ignore the downsides of your so-called impact it no longer work. I got fired for trying to have that conversation. I was not alone thinking that, but then again, the others also had their performance reviews coming up.”
On Kent Beck’s current product lifecycle thinking (3X), state of agile and his story on working at facebook.
“And if you’re inside the organization – just dump your ego somewhere, and hire an external guy, and ask him if he pairs up with you and says what you’ve been saying all along? Because people listen to the external guy. And the same goes for the external guy – pair up with an internal guy, ask him what should be changed and if you think he’s right, keep saying those things.”
“First we give it to our agile requirements team, then we give it to our agile development team who give it to our agile testing team who agily-test it and give it to our dev ops team who do devops and then we end up in the pit of despair where we still have 900 bugs and nobody can login into our online banking system”
“In the beginning of starting to go agile, everyone is always. But then life happens, and you’ll need a deep understanding of agile to paint the picture that helps senior executives understand why we’re all better off if we persevere with the transformation. But don’t spend a lot of time on explaining the mechanics of Scrum to senior executives; they really don’t care.”
“Rolling lookahead planning to manage dependencies – look ahead a couple of sprints to be able to predict what you might be needing across the teams…”
Scaling advice from the guy who popularized user stories before the boom of sterilized agile for the enterprise. Notice how you don’t try to plan dependencies for the entire quarterly-or-so-increment.
“A tendency that people involved with software have is unconditional optimism. Somehow you think it’s all going to work out OK, and all of the evidence – how we love evidence – says no, you’re wrong. But still you go on anyway.”
“When I walk around in so-called agile environments, I see a lot of dashboards, burndown charts and presentations on schedule. When I walk at Atlassian, I don’t see any of that. Every single wall is covered with stuff, helping to build shared understanding. They are not stupid enough to use Jira or Confluence for that.”
The important thing is not documentation but building shared understanding.
On average it takes 66 days to build a new habit. The range is anywhere from three weeks to six months – but start incredibly small: from something which takes no willpower, and automate that. Only then start building up.
After having run into James Clear’s talks, I decided to do a single ollie , a single pull-up and blog for 15 minutes every day. Two weeks into this so far good – and way more of each – despite the varying circumstances – than I otherwise would have done.
There is a load of support out there for helping your large company to strive towards business agility. But perhaps only a part of what you are being offered is essential and the rest is just accidental?
– And what is agile, Phaedrus, and what is not agile – Need we ask anyone to tell us these things? – Robert M. Pirsig
Skateboarding is a curious sport. Like Scrum, it’s quite simple, as well as very difficult.
And like Scrum, a skateboard is by its construct, quite simple. Even the most spread visual metaphor of the concept of the minimum viable product by Henrik Kniberg has a skateboard as the starting point. Even the most expensive longboard set-ups stay under 500$, and your average agile coach can well afford to have several set-ups for different purposes.
Essential tools
Just like agile transformation, skateboard maintenance – putting the parts together, exchanging them due to wear and tear, or switching to higher quality or otherwise more suitable gear can get quite complicated.
Now, if you have the proper parts and you know what you are doing, you can easily get away with just the following tool:
The essentials in skateboard maintenance
Here, you have 14mm, 10mm and 8mm sockets as well as an Y-shaped tool with three different screwdriver heads. Effectively, that’s all you need for skateboard maintenance.
You could think of the sockets as rolling wave budgeting, cross-functional feature teams, and working tested output for the customer to try out early and often. The different screwdriver heads could be imagined as the product owner, backlog refinement and retrospectives.
Accidental tools
When you start to improvise with the parts you’re using to put the skateboard together- the bolts and nuts you attach the trucks to the board, have low-quality bearings or wheels, or forego regular cleaning of the bearings, you’ll fairly soon find that there are quite a bit of more tools that you’ll be needing.
I have during the years needed way more than just the single multi-purpose tool in skateboard maintenance. In fact, I’ve needed the contents of an entire toolbox to deal with various problems and sometimes quite surprising scenarios.
Looking back, those problems and surprises have largely been due to the choices I’ve made out of inexperience.
I’m hoping that from the following parable you can glean some insight to your agile-scaling efforts.
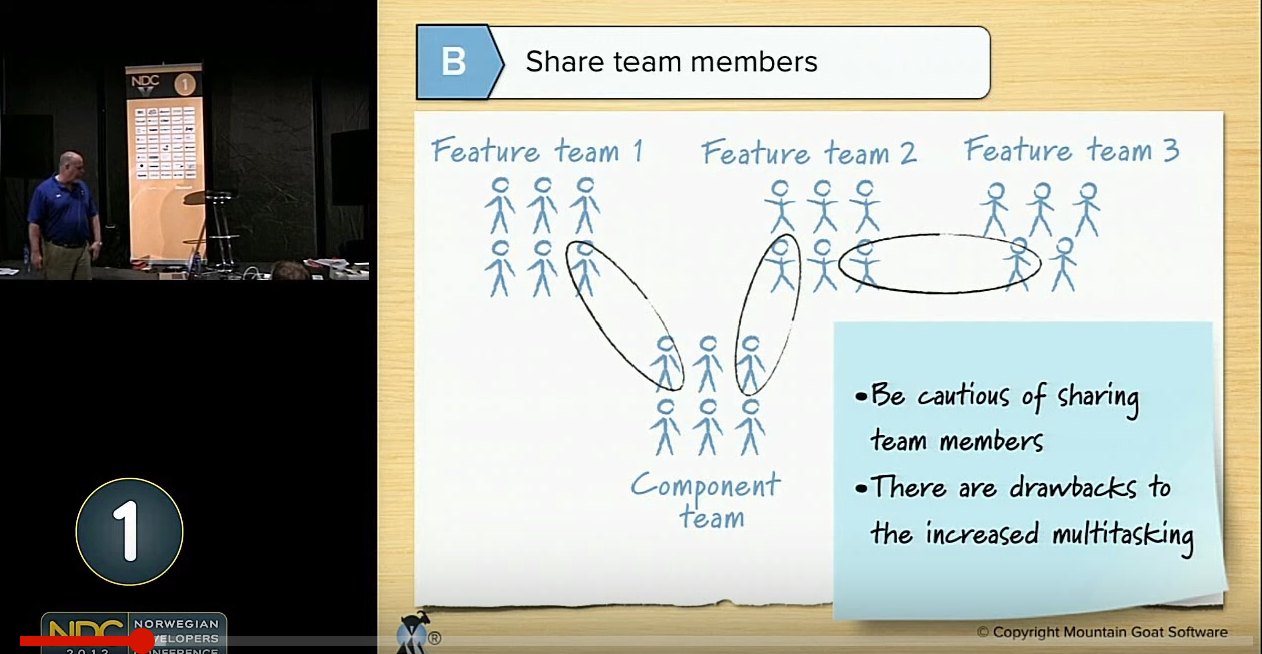
Feature teams
By far most of the problems I’ve run into in skateboard maintenance stem from improvising with the hardware – that is, the bolts and the nuts which keep the trucks in place. This, I think, is quite similar to not going through the trouble of forming cross-functional feature teams.
In an ideal scenario, you have cross-functional feature teams capable of releasing into production upon demand. And likewise, in an ideal scenario, you have bolts made of a hard metal alloy which go through the board and the trucks just enough – some 5mm or so – for you to have room to tighten the nuts.
However, unless you’ve prepared carefully by getting just the right parts, chances are that the bolts are way longer. In such a case you can’t use the multi-purpose tool any more. You’ll need a ring spanner – think of a team product owner – to get proper grip of things.
The right-sized bolts and nuts made out of a hard metal alloy from the skateshop will – just like battle-hardened agile coaches from Nitor may cost slightly more than those coaches you would get from a big chain bodyshop who is into offshoring. From those, you’ll also find too soft nuts which may also be of similar inside but different outside diameters.
Team product owners come in many sizes and shapes
So you’ll probably be needing many team product owners, pardon me, ring spanners, to keep the teams “self-organizing”.
Another challenge is that due to the longer bolts, there is quite a lot of manual fastening work to do. You’ll probably want to get some kind of power tool to help with all the tightening.
A release train engineer to help team-to-team coordination
Actually, final tightening of the bolts is meant to be done by hand, because then you’ll then have a better feel of what is ‘tight enough’.
What happens is that while you may avoid the problem of doing all the extra tightening by hand, using a power tool may lead into a bigger problem than it solves.
Now, the hardness of bolts as well as the nuts can differ quite a bit. Your average hardware store parts are quite soft in terms of the metal alloy used. The bolts you’ll get for a seemingly premium price from a skateboard shop – are way more durable.
Using a power tool it’s quite easy to mess up the screw head of the bolt or the nut, even if you have a hard-enough parts at hand. But since you need the power tool in the first place, there is a good chance that you also have a cheap, soft bolt and/or nut in the play.
Your bolt may be tightened up half-way and there’s no way to further tighten it – or, in the best case, you get it tight, but you can’t remove it any more when you wish to change trucks or add risers because you want to switch to larger diameter wheels.
Thus, you choice of bolts – think of team composition – has created some unnecessary dependencies.
And as the bolts can’t release their grip of the skateboard, you’ll need DevOps.
Who you gonna call? Call DevOps!
As a rule of thumb, when you realize that you “need DevOps”, you are already quite deep into the “you should not have ended up here in the first place but you just didn’t realize that knowledge work does not scale like digging a ditch does” territory.
Often you will be be able to squeeze the hacksaw blade in just enough to do the sawing, but you need adjustable product increment clamps – two months, I mean clamps, is OK but three is better – to hold things steady while you slowly and surely grind away the unnecessary dependencies.
A program increment
But sometimes, however, you just can’t fit the hacksaw blade into place. Here, you’ll need system team pliers to hold the the stripped screw head in place while you untighten the nut just enough for DevOps to perform its release work.
The system team
There was one time when I had stripped the bolt heads so badly that I had to give up. Even DevOps could not help me.
That story had a happy ending as I gave the board and its now-eternally-attached trucks away for my friend who for some hipster artistic reason wanted to hang an extremely beaten up -looking longboard wreck on her Kallio apartment wall.
I wonder if you could do the same with front-end code which was abandoned because the back-end functionality that was needed got stuck somewhere in a back-end team’s backlog?
To sum things up, messing up the team composition – I mean the hardware which keeps the trucks in place – is by far the most common problem I’ve had to deal with.
Note, that when dealing with teams that don’t quite fit, people often try to seek for relief from Jira plugins or a requirement level taxonomy.
How tight you keep the kingpin – the main bolt in the center of the truck – is key to all direction changes. Myself, I tend keep the trucks as loose as possible – but not looser, for that causes wheel bite – which causes to board to abruptly stop while the rider continues forward.
But eventually, you have to change the nut which governs the looseness of the kingpin. You should replace it with another high-quality and properly fitting nut from a skateboard shop, and endure the premium price.
Of course, you might have similar-looking parts lying around – like your tried and true multi-year solution roadmaps you used to update as part of your yearly budgeting process. For some strange reason, the roadmaps might – just like the nuts lying around in your toolbox, at first still look ok.
Just like that nut you found lying inside your toolbox doesn’t quite fit the main bolt of the truck – or the multi-purpose tool you had. So you get out your solution roadmap and start jamming away like you used to.
Solution roadmap
I lost two trucks trying to fit seemingly ok-looking nuts onto the kingpin. In one case, the nut got stuck halfway in between, and did not get tight enough or come off no matter how I tried. In the other case, I managed to tighten the nut ok, but the soft metal it was made of took some damage in the process, and did not come off when it was time to replace it.
Since then I have resorted for premium kingpin nuts from the skateboard shop, leave the solution roadmap to other purposes, and stick with the 14mm socket of the multi-purpose tool.
Product owner
Great product owners are like high-quality skateboard wheels. They keep everything rolling. Without them, no matter what other parts you have, nothing much happens.
Unfortunately, great product owners do not grow on trees. In your transformation, you’d naturally want to use those people who are already part of the R&D organization – line managers, business analysts, project managers, or application owners and name them team product owners.
Unless you find that person – whether from inside or outside of the development organization – who has a grasp of the whole and is able to communicate and mediate with all stakeholders, things just do not roll that well.
The product backlog
The product backlog is like skateboard bearings – your prioritization, and ultimately your entire value delivery depends on it.
Even with great product owners, your backlog, just like the skateboard bearings, is bound to collect a lot of garbage. If you don’t clean it regularly – that’s 5 times more often than you’d think if you ride in a turbulent environment – your prioritization grinds to a halt.
When this happens, the insides of the bearings fall out and the outermost ring gets tightly stuck into the wheel. Essentially, with that ring stuck, there’s no using the wheel – or rather, all the four wheels that belong to the entire set – any more.
You could think of this as the entire team of teams grinding to a halt from the perspective of delivering customer value.
Here, coaching becomes handy. You jam the head coach into wheel and onto the stuck metal ring bit, and then the lean-agile leadership keeps striking it until the impediment clears.
Head coach and lean-agile leadership getting ready to remove an impediment
This can take quite a bit of effort and patience from both the lean-agile leadership and the head coach, but in the end you either clear the blockade, or break the wheel or the head coach. So far, I have always been able to clear the blockade, but not without some complaints from the HR department. Nowadays I usually go outside to perform the needed hammering.
Another thing the head coach can be used for is when you are removing the bearings for their cleanup. After removing the wheel, you jam the head coach inside the wheel, between the bearings, and then twist real hard toget out a set of PI objectives for the business to score.
Of course that’s much harder than having the business to work with the teams on a daily basis and collaborate on a properly-sized set of user stories in full mutual understanding of the business benefits in the first place. But unless you know that, using the head coach to twist out the PI objectives is a plausible way forward.
Business collaborating with development on a daily basis
The moral of the story?
During all my endeavors, I have managed finally to learn to always go to the skateboard store to get the right-sized parts made of the right kind of material, use only high-quality wheels and clean the bearings early and often – especially those I use to skate in the rain.
And instead of dragging a big toolbox around, I can do all my gear changing with a small hand tool that is easy to carry around.
I’m not yet sure about large-scale agile, but sometimes, at least in skateboarding, less can be more.
Mitä teet, kun kohtaat arkkitehtuuri- tai osaamis- tai osastorajojen mukaan muodostuneita tiimejä? No tietysti hajotat ne ja kokoat uudelleen asiakasarvon toimittamisen ympärille. Mutta jos et voi tehdä näin, on tilanteeseen huonompia ja parempia sopeutumistapoja.
A common disease that afflicts management is the impression that “Our problems are different.” They are different, but the principles that will help are universal in nature
-Deming
Vuonna 2008 olin onnistunut myymään ketterää portfolionhallintaa tarkastelevan tutkimusprojektimme “täysjäsenyyden” noin 70 hengen kasvavaan ohjelmistopalveluja tarjoavaan yritykseen. Tutkimusprojektimme nimissä minun oli tarkoitus kehittää heidän projektisalkun hallintaansa. Oikeasti he olivat lähteneet mukaan siksi, että olimme sopineet, että samalla saadaan avullani ajettua sisään kelvollinen työkalu työtuntien kirjaamiseen.
Siinä samalla kun neuvoin tuntikirjausten tekemistä ja töiden mallintamista Agilefantiin huomasin, että ne organisaation entiteetit, joita he kutsuivat Tiimeiksi olivat itse asiassa osaamisalueittain järjestettyjä porukoita – tai “resurssipuuleja”.
Näistä porukoista sitten vedettiin kasaan projekteihin kulloinkin tarvitut kaverit. Tämä puolestaan johti siihen, että jossakin teknologiassa edistyneimmät, kuten Saara (nimi muutettu), osallistuivat useaan projektiin kerrallaan.
Aloinkin siksi hivuttamaan myös ajatusta siitä, että nämä heidän “tiiminsä” eivät muuten olekaan tiimejä. Mitäs jos pyrittäisiinkin muodostamaan ihan oikeita tiimejä? Lähdettäisiin systemaattisesti levittämään osaamista niillä alueilla, joissa yksittäiset osaajat muodostuvat pullonkaulaksi.
Kokemuksista oppineena päätin koota teille, rakkaat valeketteryytysten suota raivaavat lukijat, kasan valikoituja linkkejä. Näiden avulla pystytte toisaalta levittämään tietoisuutta siitä, miksi komponenttitiimit johtavat monenlaisiin epäoptimaalisiin organisaatiorakenteisiin ja hidastavat läpimenoaikoja, mutta toisaalta myös tietoa siitä, millaisiin kompromisseihin kannattaa suostua, jos komponentti- tai osastokohtaista organisaatiorakennetta ei ainakaan heti pysty purkamaan.
Kuivata suo…
Ketteryyden ja transformaatioiden yhteydessä puhutaan usein“kulttuurista” ja “mindsetista”. Todellisuudessa ketteryyden tärkeimmät – ja haastavimmat – kulmakivet ovat organisaation rakenteissa.
Ahmad Fahmyn artikkelissa The Rise of the Team on muutama käytännön esimerkki, miten tiimit saadaan muodostettua asiakasarvon ympärille.
…tai hanki kahluusaappaat
Harmillisen usein hyppy täysiaikaisiin tiimeihin tai etenkin osastojaon/komponenttivastuiden purkamiseen tuntuu “liian suurelta muutokselta”. Tämän vuoksi komponenttitiimit ovat useimmissa organisaatioissa vielä arkipäivää. Osa-aikainen tiimi taas on ryhmä, joka periaatteessa sisältää kaiken tarvittavan osaamisen asiakasarvoa lisäävän työn tuottamiseen (esim. featureiden A ja B edistäminen ja tuotantoonvienti), mutta heillä on muitakin merkittäviä tehtäviä. Tällainenkin organisaatiorakenne on pikemminkin sääntö kuin poikkeus.
Koska komponenttitiimit ja/tai osa-aikaiset tiimit ovat kovin yleisiä, olen aiheeseen liittyvien kirjoitusten ja ajatusten pohjalta koonnut muutaman nyrkkisäännön, joiden puitteissa toimimalla voidaan epäoptimaalisten tiimirakenteiden aiheuttamia haittoja lieventää.
Älä pidennä sprintejä vaan skaalaa seremonioiden kestoja
Ei ole epätavallista, että etenkin alkuvaiheessa esim. Scrumin sisältämien seremonioiden (sprinttisuunnittelu, dailyt, retro, demo)koetaan vievän liikaa aikaa itse tekemiseltä. Tämä johtuu siitä, että malliin kuuluvien toistuvien tapahtumien lisäksi tiimiläisten muihin vastuisiin liittyvät kokous- ym. raportointikäytännöt eivät ole poistuneet mihinkään.
Tällaisessa tilanteessa voi tiimillä olla kiusaus pidentää sprinttejä ja/tai jaksoja, jotta mallin seremoniat toistuisivat harvemmin ja aikaa jäisi enemmän itse tekemiselle. Jaksojen tai sprinttien pidentäminen ei kuitenkaan oikeasti auta, vaan pikemminkin pahentaa tilannetta, koska takaisinkytkentä harvenee.
Jos päätät vähentää seremonioita, säilytä ainakin retrospektiivi
Mitä tahansa perutkin valitsemasi mallin (esim. Scrum) seremonioista, älä peru retrospektiivejä.
Retrospektiivit ovat sekaikkeintärkeinseremonia ! Jos et usko, lue edellä olevat linkit ja tutkiskele asiaa sydämessäsi.
On myös paljon helpompi kasvattaa ketteryyttä vähän kerrassaan tiimin oman oivaltamisen, toisin sanoen hyvin fasilitoitujen retrospektiivien kautta, kuin pakottaa “teoreettista ideaalitilanteeseen perustuvaa” viitekehystä ulkoa päin.
Varmista, että tiimilläsi on alkuvaiheessa fasilitaattori
Erityisesti alkuvaiheessa seremonioiden skaalaaminen lyhyemmäksi voi olla vaikeaa, koska uuden opettelu vie oman aikansa. Hanki joku, jolla on kokemusta, osallistumaan sprinttisuunnittelujen, dailyjen, retrojen ja demojen vetämiseen.
Varaudu myös henkisesti siihen, että fasilitaattorista huolimatta näihin tapahtumiin tulee alkuvaiheessa kulumaan rutkasti “suositusta enemmän” aikaa.
Sovi tiimille koordinaattori ja tee kalenterivaraukset yhteiselle tekemiselle
Mikäli tiimissä on useampi kuin yksi jäsen, tiimin tulisi myös sopia keskuudestaan koordinaattori, jonka vastuulla on hoitaa käytännön järjestelyjä, kuten
kalenterivarausten tekeminen tiimin yhteisille tapaamisille (sprintin suunnittelut, demot ja retrot, sekä dailyt)
tapaamisten puheenjohtajana toimiminen
fasilitaattorin hankkiminen!
Scrum Master -roolihan on hengeltään näihin kaikkiin – mukaan lukien fasilitointiin – enemmän kuin sopiva. Kokemukseni mukaan Scrum Master -termin käyttäminen silloin, kun tekeminen ei ole Scrumia, tuottaa kuitenkin enemmän harmia kuin iloa.
Pysyvien tiimien tapauksessa suositeltavaa on valita koordinaattoriksi joku tiimistä, ei fasilitaattoria tai spesialistia (jotka saattavat vaihtua sprintistä toiseen) tai tuoteomistajaa (jolla on liikaa tekemistä jo valmiiksi).
Tässä tapauksessa kannattanee valita henkilöitä, joiden todennäköisesti voidaan ajatella aina olevan eri tiimeissä.














































{kind=link}
{kind=link}