So you still, even after all this time, need to use Jira in your SAFe-going organization? Or are you using Trello? Or any other tool (even if it’s a wall and some post-its) that has “workflow” as a big the visible key element? There may be a better way of leveraging it, read on…

““Get rhythm when you get the blues” – Johnny Cash
(Photo by Matthijs Smit on Unsplash)
This post is a continuation and refinement of the series where I’ve examined simpler ways of using Jira to run a SAFe-like model (see the 2020 version and the 2018 version). They also explain the problematics of using Jira to run SAFe in detail.
Re-examining this topic was spurred both two things: by the good experiences I’ve had applying the model at my current employer, DNA, and a recent page of (IMO bad) workarounds to run SAFe with Jira put together by ALM Works (the creators of e.g. Jira Structure).
Everything I wrote about in the 2020 version regarding issue types, number of boards and progress metrics still applies here, so I’ll head right into the “new” juicy bit: the planning cadence based workflow – as opposed less-than-optimal barrel-riding the waterfall type workflows you tend to encounter in the wild.
Let’s start with the latter
Riding the waterfall in the barrel workflows
Often, the workflows you see in your local Jira resemble something like this:

It is an example workflow from SAFe that’s been around since SAFe 3.0 (I think). For the above pic, I’ve combined the portfolio and the program kanban workflows from SAFe 5.1. There’ the stages have clear definitions.
But when you encounter it in the wild, the definitions of the various stages may be or may not be documented somewhere in the depths of the local Confluence. If they are, theytypically have been written years ago by SAFe-consultants who have already left the building.
But at least you can be sure that everyone – even the teams aboard the same “agile release train” using the board tend to understand the stages in their own special ways. As a result, it’s hard to assess whether the work items are actually up-to-date – and even if they weren’t, even less guidance on where they should reside.
Also take note of the embedded stage-gate and waterfall flavors in the model.
Another, even more common workflow you see out there is something like this:

A true waterfall, combined with relay-race handovers from business analysts to coders to testers and integrators, nicely cemented as the de-facto mode of working in your favourite “agile” tool. It also both separates the concerns of different specialists (as opposed to working as a team) as well as caters to the resource utilization optimization needs of your favorite big offshore delivery center.
The planning cadence based workflow
In the teams and multi-team settings I’ve coached during the past few years, I have come to suggest a workflow which is based on the planning cadence the team or organization strives to adhere to.
Here is an example of a such a workflow devised as the starting point for a multi-team Scrum organization; the columns before This sprint represent (their best guess at) the roadmap, while the columns to the right of it represent the contents and status of the ongoing sprint.
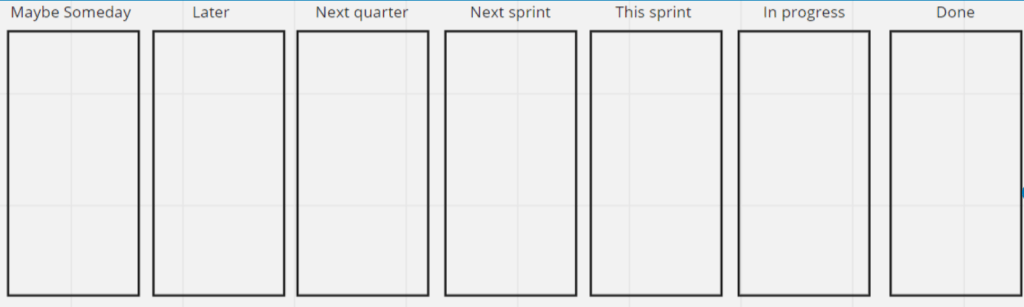
While sometimes this kind of worklow at first raises eyebrows and even the occasional WTF from even those who are really agile savvy, I’ve yet to meet people who have tried it out in practice and want to go back.
The rumour has it that in the Fall of 2021, even the highly skilled agile coaches at Nitor Delta adopted this style of workflow to manage their operational work as one of them had seen it work at DNA.
As this approach at designing the workflow seems at first to be a bit out-of-the box, I know I’m bound to encounter some setbacks. The level of transparency – and the requirements for splitting work and keeping the items up to date – admittedly can be too much for some situations. But at the time of writing this, such setbacks have not yet happened.
Note, that all the work items – be it Epics, Features, Stories, Sub-tasks, Bugs – whatever you have, are using exactly the same workflow. As in my previous Jira usage posts, you use quick filters to see what work items you’re interested in (you can even devise filters to see all the items under a particular Epic or sets of Epics), and in a similar matter, separate teams by using labels and quick filters.
The first question that people usually have how does one interpret putting an Epic into a particular column. That denotes when we expect it to be ready. For example, an Epic might reside in the Next quarter column – that is when we believe it would be ready – and all the while Stories from it are being worked on in this sprint, the next sprint and so on. Or, if we believe a Feature is supposed to be ready for release during this Sprint, it can go into the Sprint level columns. And as with my previous posts, there’s no need to use Jira’s rather convoluted and glued-on sprint functionality.
Here’s another example, used by a multi-team team organization working without a sprint cadence:
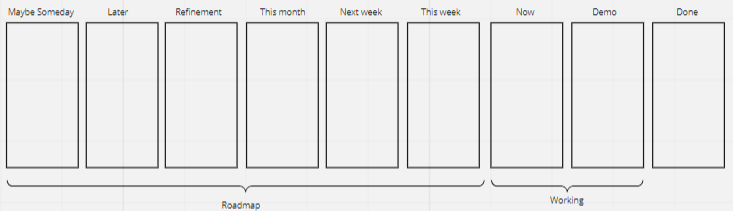
As there are no sprints, the teams use the Month and Week slots to plan their near term future. They even have a “now” column to help visualize and plan what each of them is actually working on right now.
Then, an example workflow built in the style of SAFe :
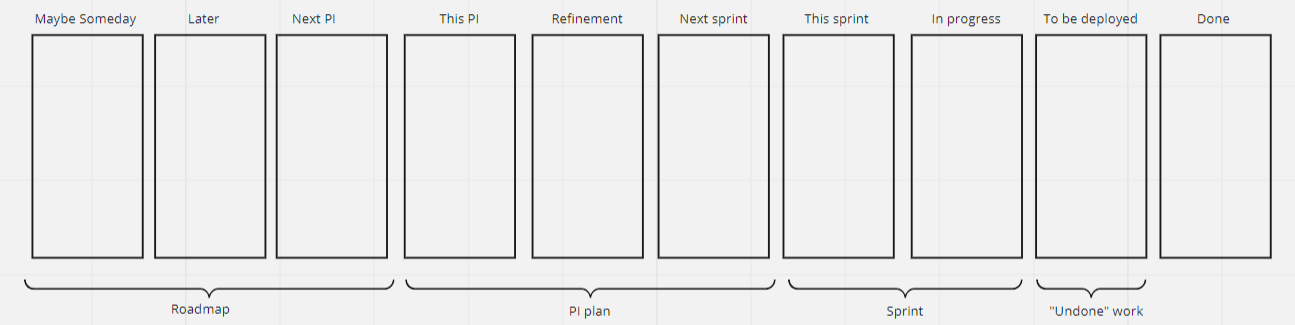
Here, we have the Next PI and This PI columns to denote the roadmap and the current plan. Newly added work items go to the Refinement column. That column should be kept empty, and as items come, it is decided where they should go to. A critical bug could go directly into the sprint and the top of the In progress column, while some discovered enhancements or important business hypotheses to be tested might go to some of the left-hand columns.
In this example, the deployment decision is something this particular agile release train cannot do it on its own, and thus that stage is not considered a part of the sprint, but rather “undone work” (a concept from LeSS that SAFe also has since then adopted).
Frequently asked questions
Every now and then, when people I work with encounter this rather unorthodox way of laying out the Jira workflow, they have questions regarding how does this model handle the things they were used to do with their previous, waterfallish workflow.
I’ve collected some questions and answers below, and will keep updating them as I run into them.
Q: How can we know whether an Epic will be completed and which column should it go to? Well, it’s an Epic, so you can’t know. But you can guess: put it to the column that you think best fits. Could be the next PI, later, or maybe someday. The aim is to communicate your guess to other parties, and the possible hard questions that follow may help you define and split the items further.
Q: If you’re using only a single board for many teams, how can the teams see and plan only their own work? Label the work per team (apply more labels if more teams are responsible) and use quick filter. And anyway, Jira doesn’t support the concept of the team, so with any workflow you’ll have to tackle this somehow.
Q: Will the board be really slow as it contains all the work items from all the teams? Yes, the board does get slower with really many items. But in my experience it will not get too slow (compared to the general sluggishness of Jira).
Q: Surely, bugs will need a different workflow? Well, fixing bugs is work, just like your stories and features. So far I’ve seen no good reasons to model the life of bugs any differently. In my opinion, the decisions when to fix which bugs are spelled out in this model rather clearly.
Q: Surely, we will need more columns to denote how the work proceeds inside a sprint? And if we add them, there will be really many columns. Certainly, if your team does not work as a team, and work gets passed around from analysts to coders to testers, additional steps to just In progress will prove useful. You can either model these things as sub-tasks, or then just add the columns. In one setting I encountered we ended up adding development, ready for integration testing, integration testing, and acceptance testing as separate columns, as the matureness of the organization in question needed it. But still, a clear win is that here, these all meant to happen and get done inside a single sprint.
Q: In our stage-gate model, we have a phase where we get a formal sign-off from the customer that the requirements are OK and we can proceed with design and development. How do you handle it in this model? My suggestion is to create sub-tasks (e.g. Signoff with customer) for such things to leave the trace. I guess I don’t have to find you references that formal sign-offs such as these can be a sign of dysfunction. Customer collaboration over contract sign-offs and so on.
Q: It’s really hard to use the columns beyond This month, as we need to split the items so small. Learning to split the work into end to end slices is hard. But gets easier as you are forced to practice it applying this model.
Q: We are using the Xray plugin for supporting quality assurance; surely the Test Plan, Test Set, Test and Test Execution will need a different workflow? This is more complicated than most of the questions I’ve run into.
As a side note, with my history as a recovering tool vendor, I find myself questioning whether XRay is some form of specialists-cementing-their-importance-and/or-separation-of-concerns (as opposed to going for fast-paced close collaboration where everyone has the title of ‘team member’) with additional tooling. Does XRay just adds buttons, knobs and other moving parts of questionable usefulness, with the the spirit of the waterfall being ever watchful…
But my biases aside, let’s take this apart.
I’ve taken the following issue type definitions from Eficode’s xRay page:
- Precondition: Defines what must be
- done before test steps can be executed
- Test Plan: Defines what tests should be executed for what version
- Test Set: A group of tests, for example all tests related to some application functionality. One test can belong to multiple test sets.
- Test: A test case and it includes test steps, actions and expected results from those
- Test execution: Represents a single execution of the test. Test executions can be created directly via Jenkins integration
Clearly, executing tests is work. If we are doing that in this sprint, they would go there; if in the next sprint, they would go there. Designing tests, test sets and test plans is work as well, so I can’t see a reason it could not be handled just like any other work.
However, one case I see where an additional workflow step could be warranted is in creating more visibility into the the case of tests which fail. While putting a failed test into a done column would clearly not work, some visibility could be lost by returning it into a previous step as well.
This might be resolved by adding a column inside a sprint: something along the lines of Failed / Could not test / Broken. If a test is failed, it goes into that column. If a Story is found broken, it will go to that column. Like this:
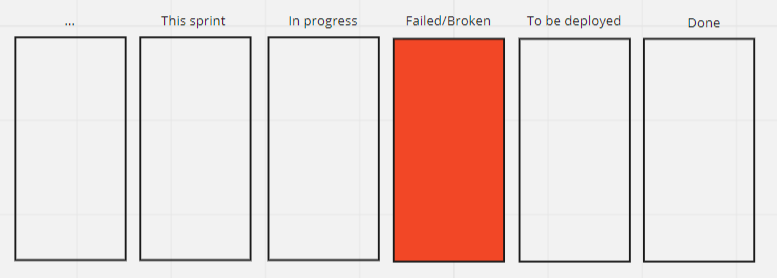
For fixing, the the Story goes back into the This sprint column, along with the failed tests, and the cycle repeats until either the test is passed (and is Done), or it is decided that the Story is postponed.
Now, I have not used XRay in practice, so I’ll return to this after further discussing with the experts who were interested in this question.
EDIT: in the end, we decided to omit the XRay items from the common board, and put a separate board for them, with a different flow. They were just “too different”.

{kind=link}
{kind=link}